In letzter Zeit habe ich eine Spielengine in C++ geschrieben. Ich benutze sie, um ein kleines Handyspiel namens Hop Out zu entwickeln. Hier ist ein Clip, den ich mit meinem iPhone 6 aufgenommen habe. (Stummschalten für den Ton!)

Hop Out ist die Art von Spiel, die ich spielen möchte: Retro-Arcade-Gameplay mit einem 3D-Cartoon-Look. Das Ziel ist es, die Farbe jedes Pads zu ändern, wie in Q*Bert.
Hop Out befindet sich noch in der Entwicklung, aber die Engine, die es antreibt, fängt an, ziemlich ausgereift zu werden, also dachte ich, ich würde hier ein paar Tipps zur Engine-Entwicklung geben.
Warum würdest du eine Spiele-Engine schreiben wollen? Es gibt viele mögliche Gründe:
- Sie sind ein Tüftler. Du liebst es, Systeme von Grund auf zu entwickeln und zu sehen, wie sie zum Leben erweckt werden.
- Du möchtest mehr über Spieleentwicklung lernen. Ich habe 14 Jahre in der Spieleindustrie verbracht und bin immer noch dabei, es herauszufinden. Ich war mir nicht einmal sicher, ob ich eine Engine von Grund auf neu schreiben könnte, denn das ist etwas ganz anderes als die täglichen Aufgaben eines Programmierers in einem großen Studio. Ich wollte es herausfinden.
- Sie mögen Kontrolle. Es ist befriedigend, den Code genau so zu organisieren, wie man es will, und zu wissen, wo sich alles zu jeder Zeit befindet.
- Du fühlst dich von klassischen Spiele-Engines wie AGI (1984), id Tech 1 (1993), Build (1995) und Branchenriesen wie Unity und Unreal inspiriert.
- Du glaubst, dass wir, die Spieleindustrie, versuchen sollten, den Prozess der Engine-Entwicklung zu entmystifizieren. Es ist ja nicht so, dass wir die Kunst, Spiele zu entwickeln, gemeistert haben. Weit gefehlt! Je mehr wir diesen Prozess untersuchen, desto größer sind unsere Chancen, ihn zu verbessern.
Die Spieleplattformen des Jahres 2017 – Handy, Konsole und PC – sind sehr leistungsfähig und in vielerlei Hinsicht einander sehr ähnlich. Bei der Entwicklung von Spiel-Engines geht es nicht mehr so sehr darum, sich mit schwacher und exotischer Hardware herumzuschlagen, wie es in der Vergangenheit der Fall war. Meiner Meinung nach geht es eher darum, mit der Komplexität zu kämpfen, die man selbst geschaffen hat. Es ist leicht, ein Monster zu erschaffen! Deshalb konzentrieren sich die Ratschläge in diesem Beitrag darauf, die Dinge überschaubar zu halten. Ich habe ihn in drei Abschnitte gegliedert:
- Verwenden Sie einen iterativen Ansatz
- Überlegen Sie zweimal, bevor Sie die Dinge zu sehr vereinheitlichen
- Seien Sie sich bewusst, dass Serialisierung ein großes Thema ist
Dieser Rat gilt für jede Art von Spiel-Engine. Ich werde Ihnen nicht sagen, wie man einen Shader schreibt, was ein Octree ist oder wie man Physik einbaut. Das sind Dinge, von denen ich annehme, dass Sie bereits wissen, dass Sie sie wissen sollten – und es hängt weitgehend von der Art des Spiels ab, das Sie machen wollen. Stattdessen habe ich absichtlich Punkte ausgewählt, die nicht allgemein bekannt sind oder über die nicht viel gesprochen wird – das sind die Punkte, die ich am interessantesten finde, wenn ich versuche, ein Thema zu entmystifizieren.
Verwenden Sie einen iterativen Ansatz
Mein erster Ratschlag ist, etwas (irgendetwas!) schnell zum Laufen zu bringen und dann zu iterieren.
Wenn möglich, beginnen Sie mit einer Beispielanwendung, die das Gerät initialisiert und etwas auf den Bildschirm zeichnet. In meinem Fall habe ich SDL heruntergeladen, Xcode-iOS/Test/TestiPhoneOS.xcodeproj geöffnet und dann das Beispiel testgles2 auf meinem iPhone ausgeführt.

Voilà! Ich hatte einen schönen sich drehenden Würfel mit OpenGL ES 2.0.
Mein nächster Schritt war, ein 3D-Modell herunterzuladen, das jemand von Mario gemacht hatte. Ich schrieb einen schnellen & schmutzigen OBJ-Dateilader – das Dateiformat ist nicht so kompliziert – und hackte die Beispielanwendung, um Mario statt eines Würfels zu rendern. Ich habe auch SDL_Image integriert, um das Laden von Texturen zu erleichtern.

Dann habe ich eine Dual-Stick-Steuerung implementiert, um Mario zu bewegen. (Am Anfang habe ich darüber nachgedacht, einen Dual-Stick-Shooter zu machen. Allerdings nicht mit Mario.)

Als Nächstes wollte ich die Skelettanimation erforschen, also öffnete ich Blender, modellierte einen Tentakel und versah ihn mit einem Zweiknochen-Skelett, das hin und her wackelte.
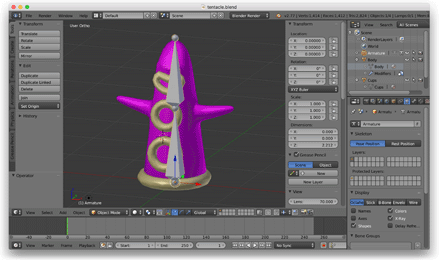
Zu diesem Zeitpunkt gab ich das OBJ-Dateiformat auf und schrieb ein Python-Skript, um benutzerdefinierte JSON-Dateien aus Blender zu exportieren. Diese JSON-Dateien beschrieben die Mesh-, Skelett- und Animationsdaten der Haut. Ich lud diese Dateien mit Hilfe einer C++-JSON-Bibliothek in das Spiel.

Nachdem das funktioniert hatte, ging ich zurück zu Blender und erstellte eine aufwändigere Figur. (Das war der erste geriggte 3D-Mensch, den ich je erstellt habe. Ich war ziemlich stolz auf ihn.)

In den nächsten Monaten unternahm ich die folgenden Schritte:
- Begann, Vektor- und Matrixfunktionen in meine eigene 3D-Mathe-Bibliothek zu integrieren.
- Ersetzte die
.xcodeprojdurch ein CMake-Projekt. - Begann, die Engine sowohl unter Windows als auch unter iOS zum Laufen zu bringen, da ich gerne in Visual Studio arbeite.
- Begann, den Code in separate „Engine“- und „Game“-Bibliotheken zu verschieben. Mit der Zeit habe ich diese in noch detailliertere Bibliotheken aufgeteilt.
- Schrieb eine separate Anwendung, um meine JSON-Dateien in Binärdaten zu konvertieren, die das Spiel direkt laden kann.
- Endlich entfernte ich alle SDL-Bibliotheken aus dem iOS-Build. (Der Windows-Build verwendet immer noch SDL.)
Der Punkt ist: Ich habe die Architektur der Engine nicht geplant, bevor ich mit der Programmierung begonnen habe. Das war eine bewusste Entscheidung. Stattdessen habe ich einfach den einfachsten Code geschrieben, der die nächste Funktion implementiert, und dann habe ich mir den Code angesehen, um zu sehen, welche Art von Architektur sich auf natürliche Weise ergibt. Mit „Engine-Architektur“ meine ich die Menge der Module, aus denen die Spiel-Engine besteht, die Abhängigkeiten zwischen diesen Modulen und die API für die Interaktion mit den einzelnen Modulen.
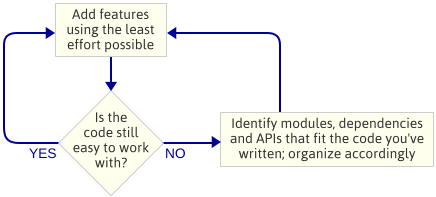
Dies ist ein iterativer Ansatz, weil er sich auf kleinere Ergebnisse konzentriert. Es funktioniert gut, wenn man eine Spiel-Engine schreibt, weil man bei jedem Schritt auf dem Weg ein laufendes Programm hat. Wenn beim Einfügen von Code in ein neues Modul etwas schief geht, können Sie Ihre Änderungen immer mit dem Code vergleichen, der vorher funktioniert hat. Natürlich gehe ich davon aus, dass Sie eine Art von Versionskontrolle verwenden.
Man könnte meinen, dass bei diesem Ansatz viel Zeit verschwendet wird, da Sie immer schlechten Code schreiben, der später bereinigt werden muss. Aber die meisten Bereinigungen beinhalten das Verschieben von Code von einer .cpp-Datei in eine andere, das Extrahieren von Funktionsdeklarationen in .h-Dateien oder ähnlich einfache Änderungen. Die Entscheidung, wohin etwas verschoben werden soll, ist der schwierige Teil, und das ist einfacher, wenn der Code bereits existiert.
Ich würde behaupten, dass im umgekehrten Fall mehr Zeit verschwendet wird: Man versucht zu sehr, eine Architektur zu entwickeln, die alles kann, was man glaubt, im Voraus zu brauchen. Zwei meiner Lieblingsartikel über die Gefahren des Over-Engineering sind The Vicious Circle of Generalization von Tomasz Dąbrowski und Don’t Let Architecture Astronauts Scare You von Joel Spolsky.
Ich sage nicht, dass man ein Problem niemals auf dem Papier lösen sollte, bevor man es in Code umsetzt. Ich sage auch nicht, dass man nicht im Voraus entscheiden sollte, welche Funktionen man haben will. Ich wusste zum Beispiel von Anfang an, dass ich wollte, dass meine Engine alle Assets in einem Hintergrund-Thread lädt. Ich habe nur nicht versucht, diese Funktion zu entwerfen oder zu implementieren, bis meine Engine tatsächlich zuerst einige Assets geladen hat.
Der iterative Ansatz hat mir eine viel elegantere Architektur beschert, als ich sie mir jemals hätte ausdenken können, wenn ich auf ein leeres Blatt Papier gestarrt hätte. Der iOS-Build meiner Engine besteht jetzt zu 100 % aus Originalcode, einschließlich einer benutzerdefinierten mathematischen Bibliothek, Container-Templates, Reflexions-/Serialisierungssystem, Rendering-Framework, Physik- und Audiomixer. Ich hatte meine Gründe, jedes dieser Module zu schreiben, aber Sie werden es vielleicht nicht für nötig halten, all diese Dinge selbst zu schreiben. Es gibt eine Menge großartiger, freizügig lizenzierter Open-Source-Bibliotheken, die Sie stattdessen vielleicht für Ihre Engine geeignet finden. GLM, Bullet Physics und die STB-Header sind nur einige interessante Beispiele.
Denken Sie zweimal nach, bevor Sie die Dinge zu sehr vereinheitlichen
Als Programmierer versuchen wir, doppelten Code zu vermeiden, und wir mögen es, wenn unser Code einem einheitlichen Stil folgt. Ich denke jedoch, dass es gut ist, diese Instinkte nicht jede Entscheidung außer Kraft setzen zu lassen.
Widerstehen Sie dem DRY-Prinzip hin und wieder
Um Ihnen ein Beispiel zu geben, enthält meine Engine mehrere „Smart Pointer“-Vorlagenklassen, ähnlich wie std::shared_ptr. Jede von ihnen hilft, Speicherlecks zu verhindern, indem sie als Wrapper um einen rohen Zeiger dient.
-
Owned<>ist für dynamisch zugewiesene Objekte, die einen einzigen Besitzer haben. -
Reference<>verwendet Referenzzählung, um einem Objekt zu erlauben, mehrere Besitzer zu haben. -
audio::AppOwned<>wird von Code außerhalb des Audiomixers verwendet. Sie ermöglicht es Spielsystemen, Objekte zu besitzen, die der Audiomixer verwendet, wie z.B. eine Stimme, die gerade abgespielt wird. -
audio::AudioHandle<>verwendet ein Referenzzählsystem innerhalb des Audiomixers.
Es mag so aussehen, als ob einige dieser Klassen die Funktionalität der anderen duplizieren, was einen Verstoß gegen das DRY-Prinzip (Don’t Repeat Yourself) darstellt. In der Tat habe ich zu Beginn der Entwicklung versucht, die bestehende Klasse Reference<> so weit wie möglich wiederzuverwenden. Ich habe jedoch festgestellt, dass die Lebensdauer eines Audioobjekts besonderen Regeln unterliegt: Wenn eine Audiostimme die Wiedergabe eines Beispiels beendet hat und das Spiel keinen Zeiger auf diese Stimme besitzt, kann die Stimme sofort in die Warteschlange gestellt und gelöscht werden. Wenn das Spiel einen Zeiger hat, sollte das Stimmenobjekt nicht gelöscht werden. Und wenn das Spiel einen Zeiger besitzt, aber der Besitzer des Zeigers zerstört wird, bevor die Stimme beendet ist, sollte die Stimme abgebrochen werden. Anstatt die Komplexität von Reference<> zu erhöhen, habe ich beschlossen, dass es praktischer ist, stattdessen separate Vorlagenklassen einzuführen.
95% der Zeit ist die Wiederverwendung von bestehendem Code der richtige Weg. Aber wenn Sie sich wie gelähmt fühlen oder feststellen, dass Sie etwas, das einmal einfach war, noch komplizierter machen, fragen Sie sich, ob etwas in der Codebasis tatsächlich zwei Dinge sein sollten.
Es ist in Ordnung, verschiedene Aufrufkonventionen zu verwenden
Eine Sache, die ich an Java nicht mag, ist, dass es Sie zwingt, jede Funktion innerhalb einer Klasse zu definieren. Das ist meiner Meinung nach unsinnig. Es lässt den Code vielleicht konsistenter aussehen, aber es ermutigt auch zum Over-Engineering und eignet sich nicht für den iterativen Ansatz, den ich zuvor beschrieben habe.
In meiner C++-Engine gehören einige Funktionen zu Klassen und andere nicht. Zum Beispiel ist jeder Feind im Spiel eine Klasse, und das meiste Verhalten des Feindes ist in dieser Klasse implementiert, wie Sie wahrscheinlich erwarten würden. Andererseits werden in meiner Engine Kugelwürfe durch den Aufruf von sphereCast(), einer Funktion im physics-Namensraum, durchgeführt. sphereCast() gehört zu keiner Klasse – es ist nur Teil des Moduls physics. Ich habe ein Build-System, das die Abhängigkeiten zwischen den Modulen verwaltet, wodurch der Code für mich gut genug organisiert ist. Diese Funktion in eine beliebige Klasse zu packen, wird die Code-Organisation in keiner Weise verbessern.
Dann gibt es noch das dynamische Dispatching, das eine Form von Polymorphismus ist. Wir müssen oft eine Funktion für ein Objekt aufrufen, ohne den genauen Typ dieses Objekts zu kennen. Der erste Instinkt eines C++-Programmierers ist, eine abstrakte Basisklasse mit virtuellen Funktionen zu definieren und diese Funktionen dann in einer abgeleiteten Klasse zu überschreiben. Das ist richtig, aber es ist nur eine Technik. Es gibt andere Techniken für dynamisches Dispatching, die nicht so viel zusätzlichen Code mit sich bringen oder andere Vorteile bieten:
- Mit C++11 wurde
std::functioneingeführt, eine bequeme Art, Callback-Funktionen zu speichern. Es ist auch möglich, eine eigene Version vonstd::functionzu schreiben, die im Debugger weniger schmerzhaft ist. - Viele Callback-Funktionen können mit einem Paar von Zeigern implementiert werden: Einem Funktionszeiger und einem undurchsichtigen Argument. Es erfordert nur einen expliziten Cast innerhalb der Callback-Funktion. Das sieht man oft in reinen C-Bibliotheken.
- Manchmal ist der zugrundeliegende Typ schon zur Kompilierzeit bekannt, und man kann den Funktionsaufruf ohne zusätzlichen Laufzeit-Overhead binden. Turf, eine Bibliothek, die ich in meiner Spiel-Engine verwende, verlässt sich häufig auf diese Technik. Siehe zum Beispiel
turf::Mutex. Es ist nur eintypedefüber eine plattformspezifische Klasse. - Manchmal ist es am einfachsten, selbst eine Tabelle mit rohen Funktionszeigern zu erstellen und zu pflegen. Ich habe diesen Ansatz in meinem Audiomixer und Serialisierungssystem verwendet. Auch der Python-Interpreter macht, wie unten erwähnt, regen Gebrauch von dieser Technik.
- Sie können Funktionszeiger sogar in einer Hash-Tabelle speichern und dabei die Funktionsnamen als Schlüssel verwenden. Ich verwende diese Technik, um Eingabeereignisse, wie z.B. Multitouch-Ereignisse, zu versenden. Es ist Teil einer Strategie, Spieleingaben aufzuzeichnen und sie mit einem Wiedergabesystem wiederzugeben.
Dynamisches Dispatching ist ein großes Thema. Ich kratze hier nur an der Oberfläche, um zu zeigen, dass es viele Möglichkeiten gibt, das zu erreichen. Je mehr Sie erweiterbaren Low-Level-Code schreiben – was in einer Spiel-Engine üblich ist -, desto mehr werden Sie Alternativen erforschen. Wenn Sie mit dieser Art der Programmierung nicht vertraut sind, ist der Python-Interpreter, der in C geschrieben ist, eine hervorragende Ressource, um davon zu lernen. Er implementiert ein leistungsfähiges Objektmodell: Jedes PyObject zeigt auf ein PyTypeObject, und jedes PyTypeObject enthält eine Tabelle von Funktionszeigern für die dynamische Abfertigung. Das Dokument Defining New Types ist ein guter Ausgangspunkt, wenn Sie gleich loslegen wollen.
Sei dir bewusst, dass Serialisierung ein großes Thema ist
Serialisierung ist die Umwandlung von Laufzeitobjekten in und aus einer Folge von Bytes. Mit anderen Worten, das Speichern und Laden von Daten.
Für viele, wenn nicht sogar die meisten Spiele-Engines werden die Spielinhalte in verschiedenen editierbaren Formaten wie .png, .json, .blend oder proprietären Formaten erstellt und dann schließlich in plattformspezifische Spielformate konvertiert, die die Engine schnell laden kann. Die letzte Anwendung in dieser Pipeline wird oft als „Cooker“ bezeichnet. Der „Cooker“ kann in ein anderes Tool integriert oder sogar auf mehrere Rechner verteilt sein. In der Regel werden der Cooker und eine Reihe von Tools zusammen mit der Spiel-Engine selbst entwickelt und gepflegt.
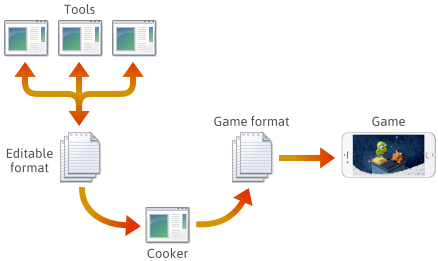
Bei der Einrichtung einer solchen Pipeline ist die Wahl des Dateiformats in jeder Phase Ihnen überlassen. Sie können einige eigene Dateiformate definieren, und diese Formate können sich weiterentwickeln, wenn Sie neue Motorfunktionen hinzufügen. Im Zuge dieser Entwicklung kann es erforderlich sein, dass bestimmte Programme mit zuvor gespeicherten Dateien kompatibel bleiben. Ganz gleich, welches Format Sie verwenden, Sie müssen es letztendlich in C++ serialisieren.
Es gibt unzählige Möglichkeiten, die Serialisierung in C++ zu implementieren. Eine ziemlich offensichtliche Möglichkeit besteht darin, load– und save-Funktionen zu den C++-Klassen hinzuzufügen, die Sie serialisieren möchten. Sie können Abwärtskompatibilität erreichen, indem Sie eine Versionsnummer in der Kopfzeile der Datei speichern und diese Nummer dann an jede load-Funktion weitergeben. Dies funktioniert, obwohl der Code schwer zu pflegen sein kann.
void load(InStream& in, u32 fileVersion) { // Load expected member variables in >> m_position; in >> m_direction; // Load a newer variable only if the file version being loaded is 2 or greater if (fileVersion >= 2) { in >> m_velocity; } }
Es ist möglich, flexibleren, weniger fehleranfälligen Serialisierungscode zu schreiben, indem man die Vorteile von Reflection nutzt – insbesondere durch die Erstellung von Laufzeitdaten, die das Layout Ihrer C++-Typen beschreiben. Um eine Vorstellung davon zu bekommen, wie Reflection bei der Serialisierung helfen kann, werfen Sie einen Blick darauf, wie Blender, ein Open-Source-Projekt, dies tut.
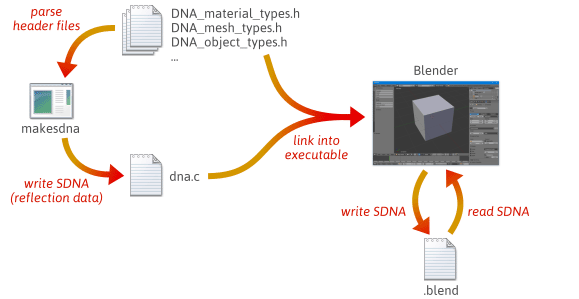
Wenn man Blender aus dem Quellcode baut, passieren viele Schritte. Zunächst wird ein benutzerdefiniertes Dienstprogramm namens makesdna kompiliert und ausgeführt. Dieses Dienstprogramm analysiert eine Reihe von C-Header-Dateien im Blender-Quellbaum und gibt dann eine kompakte Zusammenfassung aller darin definierten C-Typen in einem benutzerdefinierten Format aus, das als SDNA bekannt ist. Diese SDNA-Daten dienen als Reflexionsdaten. Die SDNA wird dann in Blender selbst eingebunden und mit jeder .blend-Datei, die Blender schreibt, gespeichert. Von diesem Zeitpunkt an vergleicht Blender jedes Mal, wenn eine .blend-Datei geladen wird, die SDNA der .blend-Datei mit der SDNA, die zur Laufzeit mit der aktuellen Version verknüpft ist, und verwendet generischen Serialisierungscode, um alle Unterschiede zu behandeln. Diese Strategie verleiht Blender ein beeindruckendes Maß an Abwärts- und Vorwärtskompatibilität. Man kann immer noch 1.0-Dateien in die neueste Version von Blender laden, und neue .blendDateien können in ältere Versionen geladen werden.
Wie Blender generieren und verwenden viele Game-Engines – und die dazugehörigen Tools – ihre eigenen Reflection-Daten. Es gibt viele Möglichkeiten, dies zu tun: Sie können Ihren eigenen C/C++-Quellcode parsen, um Typinformationen zu extrahieren, wie es Blender tut. Sie können eine separate Datenbeschreibungssprache erstellen und ein Tool schreiben, das C++-Typdefinitionen und Reflection-Daten aus dieser Sprache generiert. Sie können Präprozessormakros und C++-Vorlagen verwenden, um Reflexionsdaten zur Laufzeit zu erzeugen. Und sobald Sie Reflection-Daten zur Verfügung haben, gibt es unzählige Möglichkeiten, einen generischen Serialisierer darauf aufzubauen.
Es ist klar, dass ich viele Details auslasse. In diesem Beitrag möchte ich nur zeigen, dass es viele verschiedene Möglichkeiten gibt, Daten zu serialisieren, von denen einige sehr komplex sind. Programmierer diskutieren über Serialisierung nicht so viel wie über andere Maschinensysteme, obwohl die meisten anderen Systeme darauf angewiesen sind. Von den 96 Programmiervorträgen auf der GDC 2017 zählte ich zum Beispiel 31 Vorträge über Grafik, 11 über Online, 10 über Tools, 4 über KI, 3 über Physik, 2 über Audio – aber nur einen, der sich direkt mit Serialisierung befasste.
Versuchen Sie zumindest, eine Vorstellung davon zu haben, wie komplex Ihre Anforderungen sein werden. Wenn du ein kleines Spiel wie Flappy Bird mit nur wenigen Assets machst, musst du dir wahrscheinlich nicht allzu viele Gedanken über Serialisierung machen. Du kannst wahrscheinlich Texturen direkt aus PNG laden, und es wird gut gehen. Wenn Sie ein kompaktes Binärformat mit Abwärtskompatibilität benötigen, aber nicht selbst entwickeln wollen, sollten Sie sich die Bibliotheken von Drittanbietern wie Cereal oder Boost.Serialization ansehen. Ich glaube nicht, dass Google Protocol Buffers ideal für die Serialisierung von Spiel-Assets ist, aber es lohnt sich trotzdem, sie zu studieren.
Eine Spiele-Engine zu schreiben – selbst eine kleine – ist ein großes Unterfangen. Ich könnte noch viel mehr dazu sagen, aber für einen Beitrag dieser Länge ist das wirklich der hilfreichste Rat, den ich geben kann: Arbeiten Sie iterativ, widerstehen Sie dem Drang, den Code ein wenig zu vereinheitlichen, und seien Sie sich bewusst, dass Serialisierung ein großes Thema ist, damit Sie eine geeignete Strategie wählen können. Meiner Erfahrung nach kann jeder dieser Punkte zu einem Stolperstein werden, wenn er ignoriert wird.
Ich liebe es, Notizen zu diesem Thema zu vergleichen, daher wäre ich sehr daran interessiert, von anderen Entwicklern zu hören. Wenn Sie eine Engine geschrieben haben, sind Sie zu den gleichen Schlussfolgerungen gekommen? Und wenn Sie noch keine geschrieben haben oder nur darüber nachdenken, bin ich auch an Ihren Gedanken interessiert. Was halten Sie für eine gute Quelle, um daraus zu lernen? Welche Teile erscheinen Ihnen noch rätselhaft? Hinterlassen Sie unten einen Kommentar oder schreiben Sie mir auf Twitter!