På det seneste har jeg skrevet en spilmotor i C++. Jeg bruger den til at lave et lille mobilspil kaldet Hop Out. Her er et klip optaget fra min iPhone 6. (Unmute for lyd!)

Hop Out er den slags spil, som jeg gerne vil spille: Retro arkade gameplay med et 3D tegneserie-look. Målet er at ændre farven på hver enkelt pad, ligesom i Q*Bert.
Hop Out er stadig under udvikling, men den motor, der driver det, er begyndt at blive ret moden, så jeg tænkte, at jeg ville dele et par tips om motorudvikling her.
Hvorfor vil du skrive en spilmotor? Der er mange mulige grunde:
- Du er en tinker. Du elsker at bygge systemer fra bunden og se dem komme til live.
- Du vil gerne lære mere om spiludvikling. Jeg har brugt 14 år i spilindustrien, og jeg er stadig ved at finde ud af det. Jeg var ikke engang sikker på, at jeg kunne skrive en engine fra bunden, da det er meget forskelligt fra de daglige ansvarsområder i et programmeringsjob i et stort studie. Det ville jeg gerne finde ud af.
- Du kan godt lide kontrol. Det er tilfredsstillende at organisere koden præcis, som man ønsker det, og vide, hvor alting er hele tiden.
- Du føler dig inspireret af klassiske spilmotorer som AGI (1984), id Tech 1 (1993), Build (1995) og branchegiganter som Unity og Unreal.
- Du mener, at vi i spilbranchen bør forsøge at afmystificere motorudviklingsprocessen. Det er jo ikke sådan, at vi har mestret kunsten at lave spil. Langt fra! Jo mere vi undersøger denne proces, jo større er vores chancer for at forbedre den.
Spilplatformene i 2017 – mobil, konsol og pc – er meget kraftfulde og på mange måder ret ens. Udvikling af spilmotorer handler ikke så meget om at kæmpe med svag og eksotisk hardware, som det var før i tiden. Efter min mening handler det mere om at kæmpe med kompleksitet, som man selv har skabt. Det er nemt at skabe et monster! Derfor er rådene i dette indlæg centreret omkring at holde tingene overskuelige. Jeg har inddelt det i tre afsnit:
- Brug en iterativ tilgang
- Tænk dig godt om, før du ensretter tingene for meget
- Vær opmærksom på, at serialisering er et stort emne
Dette råd gælder for enhver form for spilmotor. Jeg vil ikke fortælle dig, hvordan du skriver en shader, hvad en octree er, eller hvordan du tilføjer fysik. Det er den slags ting, som jeg går ud fra, at du allerede ved, at du bør vide – og det afhænger i høj grad af den type spil, du vil lave. I stedet har jeg bevidst valgt punkter, som ikke synes at være almindeligt anerkendt eller omtalt – det er den slags punkter, som jeg finder mest interessante, når jeg forsøger at afmystificere et emne.
Brug en iterativ tilgang
Mit første råd er at få noget (hvad som helst!) til at køre hurtigt, og derefter iterere.
Hvis det er muligt, så start med et eksempelprogram, der initialiserer enheden og tegner noget på skærmen. I mit tilfælde downloadede jeg SDL, åbnede Xcode-iOS/Test/TestiPhoneOS.xcodeproj og kørte derefter testgles2-eksemplet på min iPhone.

Voilà! Jeg havde en dejlig snurrende terning ved hjælp af OpenGL ES 2.0.
Mit næste skridt var at downloade en 3D-model, som nogen havde lavet af Mario. Jeg skrev en hurtig & beskidt OBJ-fil loader – filformatet er ikke så kompliceret – og hackede prøveprogrammet til at gengive Mario i stedet for en kube. Jeg integrerede også SDL_Image for at hjælpe med at indlæse teksturer.

Så implementerede jeg dobbelt-stick-kontroller til at bevæge Mario rundt. (I begyndelsen overvejede jeg at lave et dual-stick-shooter. Men ikke med Mario.)

Næst ville jeg udforske skeletanimation, så jeg åbnede Blender, modellerede en tentakel og riggede den med et skelet med to knogler, der vred sig frem og tilbage.
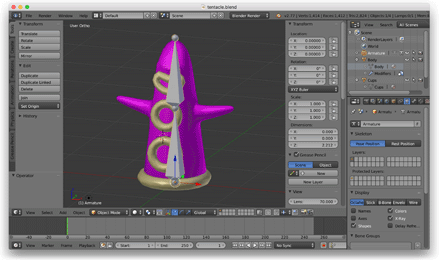
På dette tidspunkt forlod jeg OBJ-filformatet og skrev et Python-script til at eksportere brugerdefinerede JSON-filer fra Blender. Disse JSON-filer beskrev de flåede mesh-, skelet- og animationsdata. Jeg indlæste disse filer i spillet ved hjælp af et C++ JSON-bibliotek.

Når det virkede, gik jeg tilbage i Blender og lavede mere udførlige karakterer. (Dette var det første riggede 3D-menneske, jeg nogensinde skabte. Jeg var ret stolt af ham.)

I løbet af de næste par måneder tog jeg følgende skridt:
- Begyndte at udregne vektor- og matrixfunktioner i mit eget 3D-matematikbibliotek.
- Fåede
.xcodeprojerstattet med et CMake-projekt. - Fik motoren til at køre på både Windows og iOS, fordi jeg godt kan lide at arbejde i Visual Studio.
- Fik begyndt at flytte kode til separate “engine”- og “game”-biblioteker. Med tiden opdelte jeg disse i endnu mere granulære biblioteker.
- Skrevne et separat program til at konvertere mine JSON-filer til binære data, som spillet kan indlæse direkte.
- Eventuelt fjernede jeg alle SDL-biblioteker fra iOS-build’et. (Windows-bygningen bruger stadig SDL.)
Punktet er: Jeg planlagde ikke motorarkitekturen, før jeg begyndte at programmere. Det var et bevidst valg. I stedet skrev jeg bare den enkleste kode, der implementerede den næste funktion, og så kiggede jeg på koden for at se, hvilken arkitektur der opstod naturligt. Med “motorarkitektur” mener jeg det sæt af moduler, der udgør spilmotoren, afhængighederne mellem disse moduler og API’en til at interagere med hvert modul.
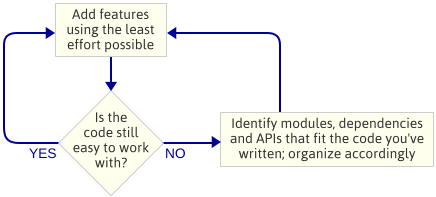
Dette er en iterativ tilgang, fordi den fokuserer på mindre leverancer. Den fungerer godt, når man skriver en spilmotor, fordi man ved hvert trin undervejs har et kørende program. Hvis noget går galt, når du indarbejder kode i et nyt modul, kan du altid sammenligne dine ændringer med den kode, der fungerede tidligere. Jeg går naturligvis ud fra, at du bruger en eller anden form for kildekontrol.
Du tror måske, at der går en masse tid til spilde ved denne fremgangsmåde, da du altid skriver dårlig kode, som skal ryddes op senere. Men det meste af oprydningen involverer flytning af kode fra en .cpp fil til en anden, udtrækning af funktionsdeklarationer til .h filer eller lige så ligetil ændringer. Det svære er at beslutte, hvor tingene skal hen, og det er nemmere at gøre, når koden allerede findes.
Jeg vil hævde, at der går mere tid til spilde ved den modsatte fremgangsmåde: At forsøge for hårdt at komme med en arkitektur, der vil gøre alt det, du tror, du har brug for på forhånd. To af mine yndlingsartikler om farerne ved over-engineering er The Vicious Circle of Generalization af Tomasz Dąbrowski og Don’t Let Architecture Astronauts Scare You af Joel Spolsky.
Jeg siger ikke, at du aldrig skal løse et problem på papiret, før du tager fat på det i kode. Jeg siger heller ikke, at du ikke skal beslutte, hvilke funktioner du vil have på forhånd. Jeg vidste f.eks. fra starten, at jeg ville have min motor til at indlæse alle assets i en baggrundstråd. Jeg prøvede bare ikke at designe eller implementere den funktion, før min motor rent faktisk indlæste nogle aktiver først.
Den iterative tilgang har givet mig en meget mere elegant arkitektur, end jeg nogensinde kunne have drømt om ved at stirre på et tomt stykke papir. iOS-bygningen af min motor er nu 100 % original kode, herunder et brugerdefineret matematisk bibliotek, containerskabeloner, refleksions-/serialiseringssystem, renderingsramme, fysik og lydmixer. Jeg havde grunde til at skrive hvert af disse moduler, men du finder det måske ikke nødvendigt at skrive alle disse ting selv. Der findes masser af gode open source-biblioteker med fri licens, som du måske finder passende til din motor i stedet. GLM, Bullet Physics og STB-headers er blot nogle få interessante eksempler.
Tænk dig om, før du ensretter tingene for meget
Som programmører forsøger vi at undgå kodedobling, og vi kan godt lide, når vores kode følger en ensartet stil. Jeg mener dog, at det er godt ikke at lade disse instinkter tilsidesætte enhver beslutning.
Resist the DRY Principle Once in a While
For at give et eksempel indeholder min motor flere “smart pointer”-skabelonklasser, der ligner ånden i std::shared_ptr. Hver enkelt hjælper med at forhindre hukommelseslækager ved at fungere som en indpakning omkring en rå pointer.
-
Owned<>er til dynamisk allokerede objekter, der har en enkelt ejer. -
Reference<>bruger referencetælling for at tillade, at et objekt kan have flere ejere. -
audio::AppOwned<>bruges af kode uden for lydmixeren. Den gør det muligt for spilsystemer at eje objekter, som lydmixeren bruger, f.eks. en stemme, der afspilles i øjeblikket. -
audio::AudioHandle<>bruger et referencetællingssystem internt i lydmixeren.
Det kan se ud som om nogle af disse klasser duplikerer de andres funktionalitet, hvilket er i strid med DRY-princippet (Don’t Repeat Yourself). Faktisk forsøgte jeg tidligere i udviklingen at genbruge den eksisterende Reference<>-klasse så meget som muligt. Jeg fandt imidlertid ud af, at levetiden for et lydobjekt er underlagt særlige regler: Hvis en lydstemme er færdig med at afspille en prøve, og spillet ikke har en pointer til den pågældende stemme, kan stemmen sættes i kø til sletning med det samme. Hvis spillet har en pointer, skal stemmeobjektet ikke slettes. Og hvis spillet har en pointer, men pointerens ejer bliver ødelagt, før stemmen er slut, skal stemmen annulleres. I stedet for at tilføje kompleksitet til Reference<> besluttede jeg, at det var mere praktisk at indføre separate skabelonklasser i stedet.
95% af tiden er genbrug af eksisterende kode den rigtige løsning. Men hvis du begynder at føle dig lammet eller finder dig selv ved at tilføje kompleksitet til noget, der engang var simpelt, så spørg dig selv, om noget i kodebasen faktisk bør være to ting.
Det er OK at bruge forskellige kaldskonventioner
En ting, jeg ikke bryder mig om ved Java, er, at det tvinger dig til at definere hver enkelt funktion inde i en klasse. Det er noget vrøvl, efter min mening. Det får måske din kode til at se mere konsistent ud, men det tilskynder også til over-engineering og egner sig ikke godt til den iterative tilgang, som jeg beskrev tidligere.
I min C++-motor hører nogle funktioner til klasser, og andre gør ikke. F.eks. er alle fjender i spillet en klasse, og det meste af fjendens adfærd er implementeret inden for denne klasse, som du sikkert ville forvente. På den anden side udføres kuglecasts i min motor ved at kalde sphereCast(), en funktion i physics-navneområdet. sphereCast() hører ikke til nogen klasse – den er blot en del af physics-modulet. Jeg har et build-system, der håndterer afhængigheder mellem moduler, hvilket holder koden organiseret godt nok for mig. At pakke denne funktion ind i en vilkårlig klasse vil ikke forbedre kodeorganiseringen på nogen meningsfuld måde.
Så er der dynamisk dispatch, som er en form for polymorphisme. Vi har ofte brug for at kalde en funktion for et objekt uden at kende den nøjagtige type af dette objekt. En C++-programmørs første instinkt er at definere en abstrakt basisklasse med virtuelle funktioner og derefter overstyre disse funktioner i en afledt klasse. Det er gyldigt, men det er kun én teknik. Der findes andre dynamiske dispatch-teknikker, som ikke introducerer så meget ekstra kode, eller som giver andre fordele:
- C++11 introducerede
std::function, som er en praktisk måde at gemme callback-funktioner på. Det er også muligt at skrive sin egen version afstd::function, som er mindre smertefuld at træde ind i i debuggeren. - Mange callback-funktioner kan implementeres med et par pointere: En funktionsviseren og et uigennemsigtigt argument. Det kræver blot en eksplicit cast inde i callback-funktionen. Du ser dette meget i rene C-biblioteker.
- Sommetider er den underliggende type faktisk kendt på kompileringstidspunktet, og du kan binde funktionskaldet uden yderligere løbetidsoverhead. Turf, et bibliotek, som jeg bruger i min spilmotor, er meget afhængig af denne teknik. Se
turf::Mutexfor eksempel. Det er bare entypedefover en platformsspecifik klasse. - Sommetider er den mest ligetil tilgang at opbygge og vedligeholde en tabel med rå funktionsvisere selv. Jeg brugte denne fremgangsmåde i mit lydmixer- og serialiseringssystem. Python-fortolkeren gør også stor brug af denne teknik, som nævnt nedenfor.
- Du kan endda gemme funktionsvisere i en hashtabel, hvor du bruger funktionsnavnene som nøgler. Jeg bruger denne teknik til at sende inputhændelser, f.eks. multitouch-hændelser. Det er en del af en strategi til at registrere spilinput og afspille dem med et gengivelsessystem.
Dynamisk dispatch er et stort emne. Jeg kradser kun i overfladen for at vise, at der er mange måder at opnå det på. Jo mere du skriver udvidelig kode på lavt niveau – hvilket er almindeligt i en spilmotor – jo mere vil du finde dig selv i at udforske alternativer. Hvis du ikke er vant til denne form for programmering, er Python-fortolkeren, som er skrevet i C, en glimrende ressource at lære fra. Den implementerer en kraftfuld objektmodel: Hver PyObject peger på en PyTypeObject, og hver PyTypeObject indeholder en tabel med funktionsvisere til dynamisk afsendelse. Dokumentet Defining New Types er et godt udgangspunkt, hvis du vil springe direkte ind i det.
Vær opmærksom på, at serialisering er et stort emne
Serialisering er den handling, der består i at konvertere runtimeobjekter til og fra en sekvens af bytes. Med andre ord, lagring og indlæsning af data.
For mange, hvis ikke de fleste spilmotorer oprettes spilindholdet i forskellige redigerbare formater som .png, .json, .blend eller proprietære formater, hvorefter det til sidst konverteres til platformsspecifikke spilformater, som motoren hurtigt kan indlæse. Det sidste program i denne pipeline betegnes ofte som en “cooker”. Cookeren kan være integreret i et andet værktøj eller endda fordelt på flere maskiner. Normalt udvikles og vedligeholdes cookeren og en række værktøjer sammen med selve spilmotoren.
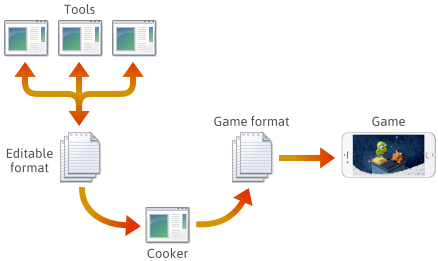
Når man opsætter en sådan pipeline, er valget af filformat på hvert trin op til en selv. Du kan definere nogle af dine egne filformater, og disse formater kan udvikle sig, efterhånden som du tilføjer motorfunktioner. Efterhånden som de udvikler sig, kan du finde det nødvendigt at holde visse programmer kompatible med tidligere gemte filer. Uanset hvilket format, skal du i sidste ende serialisere det i C++.
Der er utallige måder at implementere serialisering i C++ på. En ret indlysende måde er at tilføje load og save-funktioner til de C++-klasser, du ønsker at serialisere. Du kan opnå bagudkompatibilitet ved at lagre et versionsnummer i filhovedet og derefter sende dette nummer ind i hver load-funktion. Dette fungerer, selv om koden kan blive besværlig at vedligeholde.
void load(InStream& in, u32 fileVersion) { // Load expected member variables in >> m_position; in >> m_direction; // Load a newer variable only if the file version being loaded is 2 or greater if (fileVersion >= 2) { in >> m_velocity; } }
Det er muligt at skrive mere fleksibel og mindre fejlbehæftet serialiseringskode ved at udnytte refleksion – nærmere bestemt ved at oprette runtime-data, der beskriver layoutet af dine C++-typer. For at få et hurtigt indtryk af, hvordan reflection kan hjælpe med serialisering, kan du se på, hvordan Blender, et open source-projekt, gør det.
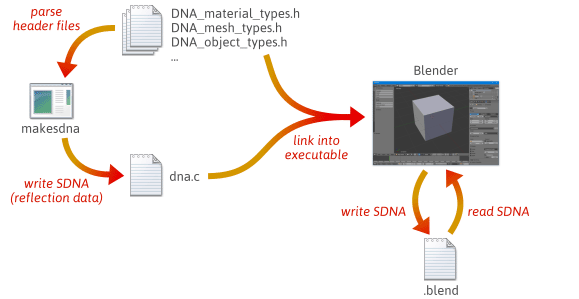
Når du bygger Blender fra kildekode, sker der mange trin. Først kompileres og køres et brugerdefineret hjælpeprogram ved navn makesdna. Dette hjælpeprogram analyserer et sæt C header-filer i Blender-kildetræet og udsender derefter et kompakt resumé af alle C-typer, der er defineret i dem, i et brugerdefineret format, der er kendt som SDNA. Disse SDNA-data tjener som refleksionsdata. SDNA’en linkes derefter ind i Blender selv og gemmes sammen med hver .blend fil, som Blender skriver. Fra det tidspunkt sammenligner Blender, hver gang Blender indlæser en .blend-fil, .blend-filens SDNA med SDNA’en, der er linket til den aktuelle version ved kørselstid, og bruger generisk serialiseringskode til at håndtere eventuelle forskelle. Denne strategi giver Blender en imponerende grad af bagud- og fremadkompatibilitet. Du kan stadig indlæse 1.0-filer i den nyeste version af Blender, og nye .blend-filer kan indlæses i ældre versioner.
Som Blender genererer og bruger mange spilmotorer – og deres tilhørende værktøjer – deres egne reflection-data. Der er mange måder at gøre det på: Du kan analysere din egen C/C++-kildekode for at udtrække typeoplysninger, som Blender gør. Du kan oprette et separat databeskrivelsessprog og skrive et værktøj til at generere C++-typedefinitioner og refleksionsdata fra dette sprog. Du kan bruge præprocessormakroer og C++-skabeloner til at generere refleksionsdata på køretid. Og når du først har refleksionsdata til rådighed, er der utallige måder at skrive en generisk serializer oven på det.
Det er klart, at jeg udelader en masse detaljer. I dette indlæg ønsker jeg blot at vise, at der er mange forskellige måder at serialisere data på, hvoraf nogle er meget komplekse. Programmører diskuterer bare ikke serialisering så meget som andre motorsystemer, selv om de fleste andre systemer er afhængige af det. For eksempel talte jeg ud af de 96 programmeringsforedrag, der blev holdt på GDC 2017, 31 foredrag om grafik, 11 om online, 10 om værktøjer, 4 om AI, 3 om fysik, 2 om lyd – men kun ét, der berørte serialisering direkte.
Prøv som minimum at have en idé om, hvor komplekse dine behov vil være. Hvis du laver et lille spil som Flappy Bird, med kun få assets, behøver du sandsynligvis ikke tænke så meget over serialisering. Du kan sandsynligvis indlæse teksturer direkte fra PNG, og det vil være fint. Hvis du har brug for et kompakt binært format med bagudkompatibilitet, men ikke ønsker at udvikle dit eget, kan du tage et kig på tredjepartsbiblioteker som Cereal eller Boost.Serialization. Jeg tror ikke, at Google Protocol Buffers er ideelle til serialisering af spilaktiver, men de er ikke desto mindre værd at studere.
At skrive en spilmotor – selv en lille en – er en stor opgave. Der er meget mere, jeg kunne sige om det, men for et indlæg af denne længde er det ærligt talt det mest nyttige råd, jeg kan komme i tanke om at give: Arbejd iterativt, modstå trangen til at ensrette koden en smule, og vid, at serialisering er et stort emne, så du kan vælge en passende strategi. Min erfaring er, at hver af disse ting kan blive en snublesten, hvis de ignoreres.
Jeg elsker at sammenligne noter om disse ting, så jeg ville være virkelig interesseret i at høre fra andre udviklere. Hvis du har skrevet en motor, førte dine erfaringer dig så til nogle af de samme konklusioner? Og hvis du ikke har skrevet en, eller hvis du bare overvejer det, er jeg også interesseret i dine tanker. Hvad anser du for at være en god ressource at lære af? Hvilke dele virker stadig mystiske for dig? Du er velkommen til at efterlade en kommentar nedenfor eller slå mig op på Twitter!