Récemment, j’ai écrit un moteur de jeu en C++. Je l’utilise pour faire un petit jeu mobile appelé Hop Out. Voici un clip capturé à partir de mon iPhone 6. (Unmute pour le son !)

Hop Out est le genre de jeu auquel je veux jouer : Un jeu d’arcade rétro avec un look de dessin animé en 3D. Le but est de changer la couleur de chaque pad, comme dans Q*Bert.
Hop Out est encore en développement, mais le moteur qui le propulse commence à devenir assez mature, alors j’ai pensé que je partagerais ici quelques conseils sur le développement de moteurs.
Pourquoi voudriez-vous écrire un moteur de jeu ? Il y a plusieurs raisons possibles :
- Vous êtes un bricoleur. Vous aimez construire des systèmes à partir de la base et les voir prendre vie.
- Vous voulez en apprendre davantage sur le développement de jeux. J’ai passé 14 ans dans l’industrie du jeu et je suis toujours en train de le découvrir. Je n’étais même pas sûr de pouvoir écrire un moteur à partir de rien, car c’est très différent des responsabilités quotidiennes d’un poste de programmation dans un grand studio. Je voulais le découvrir.
- Vous aimez le contrôle. C’est satisfaisant d’organiser le code exactement comme vous le voulez, en sachant où tout se trouve à tout moment.
- Vous vous sentez inspiré par les moteurs de jeu classiques comme AGI (1984), id Tech 1 (1993), Build (1995), et les géants de l’industrie comme Unity et Unreal.
- Vous croyez que nous, l’industrie du jeu, devrions essayer de démystifier le processus de développement du moteur. Ce n’est pas comme si nous avions maîtrisé l’art de créer des jeux. Loin de là ! Plus nous examinons ce processus, plus nous avons de chances de l’améliorer.
Les plateformes de jeu de 2017 – mobile, console et PC – sont très puissantes et, à bien des égards, assez semblables les unes aux autres. Le développement de moteurs de jeux ne consiste pas tant à se battre avec du matériel faible et exotique, comme c’était le cas par le passé. À mon avis, il s’agit plutôt de se battre avec la complexité que l’on crée soi-même. Il est facile de créer un monstre ! C’est pourquoi les conseils de cet article sont axés sur la nécessité de garder les choses gérables. Je l’ai organisé en trois sections :
- Utiliser une approche itérative
- Réfléchir à deux fois avant de trop unifier les choses
- Savoir que la sérialisation est un gros sujet
Ces conseils s’appliquent à tout type de moteur de jeu. Je ne vais pas vous dire comment écrire un shader, ce qu’est un octree, ou comment ajouter de la physique. C’est le genre de choses que, je suppose, vous savez déjà que vous devriez savoir – et cela dépend largement du type de jeu que vous voulez faire. Au lieu de cela, j’ai délibérément choisi des points qui ne semblent pas être largement reconnus ou parlés – ce sont les types de points que je trouve les plus intéressants quand j’essaie de démystifier un sujet.
Utiliser une approche itérative
Mon premier conseil est d’obtenir quelque chose (n’importe quoi !) en cours d’exécution rapidement, puis d’itérer.
Si possible, commencez avec un exemple d’application qui initialise le périphérique et dessine quelque chose sur l’écran. Dans mon cas, j’ai téléchargé SDL, ouvert Xcode-iOS/Test/TestiPhoneOS.xcodeproj, puis exécuté l’échantillon testgles2 sur mon iPhone.

Voilà ! J’avais un joli cube qui tournait en utilisant OpenGL ES 2.0.
Ma prochaine étape était de télécharger un modèle 3D que quelqu’un a fait de Mario. J’ai écrit un rapide &chargeur de fichier OBJ sale – le format de fichier n’est pas si compliqué – et j’ai piraté l’application exemple pour rendre Mario au lieu d’un cube. J’ai également intégré SDL_Image pour aider à charger les textures.

Puis j’ai implémenté des contrôles à deux sticks pour déplacer Mario. (Au début, j’envisageais de faire un jeu de tir à deux sticks. Pas avec Mario, cependant.)

Puis, je voulais explorer l’animation squelettique, donc j’ai ouvert Blender, modélisé un tentacule, et l’ai riggé avec un squelette à deux os qui se tortillait d’avant en arrière.
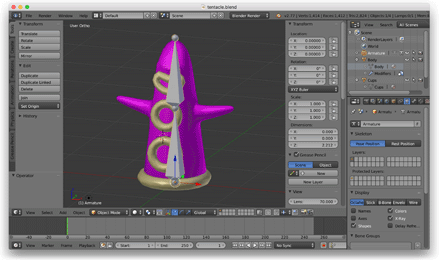
À ce stade, j’ai abandonné le format de fichier OBJ et écrit un script Python pour exporter des fichiers JSON personnalisés depuis Blender. Ces fichiers JSON décrivaient le maillage dépouillé, le squelette et les données d’animation. J’ai chargé ces fichiers dans le jeu à l’aide d’une bibliothèque JSON C++.

Une fois que cela a fonctionné, je suis retourné dans Blender et j’ai fait un personnage plus élaboré. (C’était le premier humain 3D rigged que j’ai créé. J’étais assez fier de lui.)

Au cours des mois suivants, j’ai pris les mesures suivantes :
- J’ai commencé à factoriser des fonctions vectorielles et matricielles dans ma propre bibliothèque mathématique 3D.
- Remplacé le
.xcodeprojavec un projet CMake. - A fait fonctionner le moteur à la fois sur Windows et iOS, parce que j’aime travailler dans Visual Studio.
- Commencé à déplacer le code dans des bibliothèques séparées « moteur » et « jeu ». Au fil du temps, j’ai divisé celles-ci en bibliothèques encore plus granulaires.
- Écrire une application séparée pour convertir mes fichiers JSON en données binaires que le jeu peut charger directement.
- Éventuellement, supprimer toutes les bibliothèques SDL de la build iOS. (La build Windows utilise toujours SDL.)
Le point est : Je n’ai pas planifié l’architecture du moteur avant de commencer à programmer. C’était un choix délibéré. Au lieu de cela, j’ai juste écrit le code le plus simple qui implémentait la fonctionnalité suivante, puis je regardais le code pour voir quel type d’architecture émergeait naturellement. Par « architecture du moteur », j’entends l’ensemble des modules qui composent le moteur de jeu, les dépendances entre ces modules et l’API pour interagir avec chaque module.
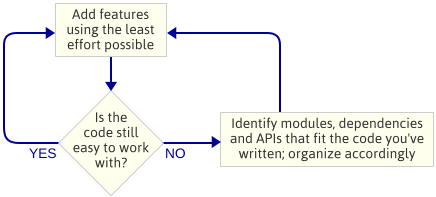
C’est une approche itérative parce qu’elle se concentre sur des livrables plus petits. Elle fonctionne bien lors de l’écriture d’un moteur de jeu car, à chaque étape du processus, vous avez un programme en cours d’exécution. Si quelque chose ne va pas lorsque vous intégrez du code dans un nouveau module, vous pouvez toujours comparer vos modifications avec le code qui fonctionnait auparavant. Évidemment, je suppose que vous utilisez une sorte de contrôle de source.
Vous pourriez penser que beaucoup de temps est perdu dans cette approche, puisque vous écrivez toujours du mauvais code qui doit être nettoyé plus tard. Mais la plupart des nettoyages impliquent le déplacement de code d’un fichier .cpp à un autre, l’extraction de déclarations de fonctions dans des fichiers .h, ou des changements tout aussi simples. Décider où les choses doivent aller est la partie difficile, et c’est plus facile à faire lorsque le code existe déjà.
Je dirais que plus de temps est perdu dans l’approche opposée : Essayer trop fort de venir avec une architecture qui fera tout ce que vous pensez que vous aurez besoin à l’avance. Deux de mes articles préférés sur les périls de la sur-ingénierie sont The Vicious Circle of Generalization de Tomasz Dąbrowski et Don’t Let Architecture Astronauts Scare You de Joel Spolsky.
Je ne dis pas que vous ne devriez jamais résoudre un problème sur papier avant de vous y attaquer en code. Je ne dis pas non plus que vous ne devriez pas décider des fonctionnalités que vous voulez à l’avance. Par exemple, je savais dès le début que je voulais que mon moteur charge tous les actifs dans un thread en arrière-plan. Je n’ai simplement pas essayé de concevoir ou d’implémenter cette fonctionnalité jusqu’à ce que mon moteur charge effectivement quelques actifs d’abord.
L’approche itérative m’a donné une architecture beaucoup plus élégante que je n’aurais jamais pu rêver en fixant une feuille de papier blanche. La construction iOS de mon moteur est maintenant composée à 100% de code original, y compris une bibliothèque mathématique personnalisée, des modèles de conteneurs, un système de réflexion/sérialisation, un cadre de rendu, une physique et un mélangeur audio. J’avais des raisons d’écrire chacun de ces modules, mais vous ne trouverez peut-être pas nécessaire d’écrire toutes ces choses vous-même. Il y a beaucoup de bibliothèques open source sous licence permissive que vous pourriez trouver appropriées pour votre moteur. GLM, Bullet Physics et les en-têtes STB ne sont que quelques exemples intéressants.
Pensez-y à deux fois avant de trop unifier les choses
En tant que programmeurs, nous essayons d’éviter la duplication du code, et nous aimons quand notre code suit un style uniforme. Cependant, je pense qu’il est bon de ne pas laisser ces instincts prendre le dessus sur chaque décision.
Résister au principe DRY une fois de temps en temps
Pour vous donner un exemple, mon moteur contient plusieurs classes de template de « pointeur intelligent », similaires dans l’esprit à std::shared_ptr. Chacune d’entre elles aide à prévenir les fuites de mémoire en servant d’enveloppe autour d’un pointeur brut.
-
Owned<>est destinée aux objets alloués dynamiquement qui ont un seul propriétaire. -
Reference<>utilise le comptage de références pour permettre à un objet d’avoir plusieurs propriétaires. -
audio::AppOwned<>est utilisée par le code en dehors du mixeur audio. Il permet aux systèmes de jeu de posséder des objets que le mélangeur audio utilise, comme une voix en cours de lecture. -
audio::AudioHandle<>utilise un système de comptage de références interne au mélangeur audio.
Il peut sembler que certaines de ces classes dupliquent la fonctionnalité des autres, en violation du principe DRY (Don’t Repeat Yourself). En effet, plus tôt dans le développement, j’ai essayé de réutiliser la classe existante Reference<> autant que possible. Cependant, j’ai découvert que la durée de vie d’un objet audio est régie par des règles spéciales : Si une voix audio a fini de jouer un échantillon, et que le jeu ne détient pas de pointeur vers cette voix, la voix peut être mise en file d’attente pour être supprimée immédiatement. Si le jeu détient un pointeur, alors l’objet voix ne doit pas être supprimé. Et si le jeu détient un pointeur, mais que le propriétaire du pointeur est détruit avant que la voix ne soit terminée, la voix doit être annulée. Plutôt que d’ajouter de la complexité à Reference<>, j’ai décidé qu’il était plus pratique d’introduire des classes de modèles distinctes à la place.
95% du temps, la réutilisation du code existant est la voie à suivre. Mais si vous commencez à vous sentir paralysé, ou si vous vous retrouvez à ajouter de la complexité à quelque chose qui était autrefois simple, demandez-vous si quelque chose dans le codebase devrait en fait être deux choses.
C’est OK d’utiliser différentes conventions d’appel
Une chose que je n’aime pas à propos de Java est qu’il vous oblige à définir chaque fonction à l’intérieur d’une classe. C’est un non-sens, à mon avis. Cela peut rendre votre code plus cohérent, mais cela encourage aussi la sur-ingénierie et ne se prête pas bien à l’approche itérative que j’ai décrite plus tôt.
Dans mon moteur C++, certaines fonctions appartiennent à des classes et d’autres non. Par exemple, chaque ennemi dans le jeu est une classe, et la plupart du comportement de l’ennemi est implémenté à l’intérieur de cette classe, comme vous vous y attendez probablement. D’autre part, les castings de sphères dans mon moteur sont effectués en appelant sphereCast(), une fonction dans l’espace de noms physics. sphereCast() n’appartient à aucune classe – elle fait simplement partie du module physics. J’ai un système de construction qui gère les dépendances entre les modules, ce qui garde le code organisé assez bien pour moi. Envelopper cette fonction à l’intérieur d’une classe arbitraire n’améliorera pas l’organisation du code de manière significative.
Puis il y a la répartition dynamique, qui est une forme de polymorphisme. Nous avons souvent besoin d’appeler une fonction pour un objet sans connaître le type exact de cet objet. Le premier réflexe d’un programmeur C++ est de définir une classe de base abstraite avec des fonctions virtuelles, puis de surcharger ces fonctions dans une classe dérivée. C’est valable, mais ce n’est qu’une technique parmi d’autres. Il existe d’autres techniques de répartition dynamique qui n’introduisent pas autant de code supplémentaire, ou qui apportent d’autres avantages:
- C++11 a introduit
std::function, qui est un moyen pratique de stocker les fonctions de rappel. Il est également possible d’écrire votre propre version destd::functionqui est moins douloureuse à pénétrer dans le débogueur. - De nombreuses fonctions de rappel peuvent être mises en œuvre avec une paire de pointeurs : Un pointeur de fonction et un argument opaque. Cela nécessite juste un cast explicite à l’intérieur de la fonction callback. Vous voyez cela beaucoup dans les bibliothèques C pures.
- Parfois, le type sous-jacent est en fait connu au moment de la compilation, et vous pouvez lier l’appel de fonction sans aucune surcharge d’exécution supplémentaire. Turf, une bibliothèque que j’utilise dans mon moteur de jeu, s’appuie beaucoup sur cette technique. Voir
turf::Mutexpar exemple. C’est juste untypedefsur une classe spécifique à la plateforme. - Parfois, l’approche la plus directe est de construire et de maintenir vous-même une table de pointeurs de fonctions brutes. J’ai utilisé cette approche dans mon mélangeur audio et mon système de sérialisation. L’interpréteur Python fait également un usage intensif de cette technique, comme mentionné ci-dessous.
- Vous pouvez même stocker les pointeurs de fonction dans une table de hachage, en utilisant les noms de fonction comme clés. J’utilise cette technique pour dispatcher les événements d’entrée, tels que les événements multitouch. Cela fait partie d’une stratégie pour enregistrer les entrées du jeu et les rejouer avec un système de relecture.
La répartition dynamique est un grand sujet. Je ne fais qu’effleurer la surface pour montrer qu’il existe de nombreuses façons de le réaliser. Plus vous écrivez du code de bas niveau extensible – ce qui est courant dans un moteur de jeu – plus vous vous retrouverez à explorer des alternatives. Si vous n’êtes pas habitué à ce type de programmation, l’interpréteur Python, qui est écrit en C, est une excellente ressource pour apprendre. Il met en œuvre un puissant modèle objet : Chaque PyObject pointe vers un PyTypeObject, et chaque PyTypeObject contient un tableau de pointeurs de fonctions pour la répartition dynamique. Le document Defining New Types est un bon point de départ si vous voulez sauter directement dedans.
Soyez conscient que la sérialisation est un grand sujet
La sérialisation est l’acte de convertir des objets d’exécution vers et depuis une séquence d’octets. En d’autres termes, l’enregistrement et le chargement de données.
Pour beaucoup, sinon la plupart des moteurs de jeu, le contenu du jeu est créé dans divers formats modifiables tels que .png, .json, .blend ou des formats propriétaires, puis finalement converti en formats de jeu spécifiques à la plateforme que le moteur peut charger rapidement. La dernière application de ce pipeline est souvent appelée « cooker ». Le cooker peut être intégré à un autre outil, ou même réparti sur plusieurs machines. Habituellement, le cuiseur et un certain nombre d’outils sont développés et maintenus en tandem avec le moteur de jeu lui-même.
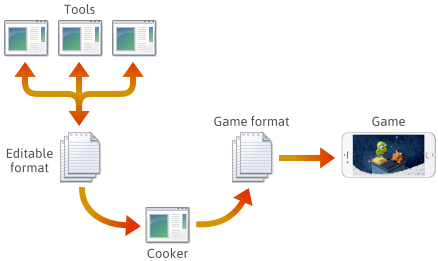
Lors de la mise en place d’un tel pipeline, le choix du format de fichier à chaque étape vous appartient. Vous pourriez définir certains formats de fichier de votre propre chef, et ces formats pourraient évoluer au fur et à mesure que vous ajoutez des fonctionnalités du moteur. Au fur et à mesure de leur évolution, vous pourrez juger nécessaire de maintenir la compatibilité de certains programmes avec les fichiers enregistrés précédemment. Quel que soit le format, vous aurez finalement besoin de le sérialiser en C++.
Il existe d’innombrables façons d’implémenter la sérialisation en C++. Une façon assez évidente est d’ajouter des fonctions load et save aux classes C++ que vous voulez sérialiser. Vous pouvez obtenir une compatibilité ascendante en stockant un numéro de version dans l’en-tête du fichier, puis en passant ce numéro dans chaque fonction load. Cela fonctionne, bien que le code puisse devenir lourd à maintenir.
void load(InStream& in, u32 fileVersion) { // Load expected member variables in >> m_position; in >> m_direction; // Load a newer variable only if the file version being loaded is 2 or greater if (fileVersion >= 2) { in >> m_velocity; } }
Il est possible d’écrire un code de sérialisation plus flexible et moins sujet aux erreurs en tirant parti de la réflexion – plus précisément, en créant des données d’exécution qui décrivent la disposition de vos types C++. Pour avoir une idée rapide de la façon dont la réflexion peut aider à la sérialisation, jetez un coup d’œil à la façon dont Blender, un projet open source, le fait.
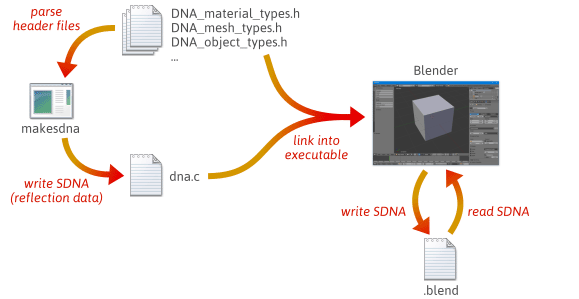
Lorsque vous construisez Blender à partir du code source, plusieurs étapes se produisent. Tout d’abord, un utilitaire personnalisé nommé makesdna est compilé et exécuté. Cet utilitaire analyse un ensemble de fichiers d’en-tête C dans l’arbre source de Blender, puis produit un résumé compact de tous les types C définis à l’intérieur, dans un format personnalisé connu sous le nom de SDNA. Ces données SDNA servent de données de réflexion. Le SDNA est ensuite lié à Blender lui-même, et sauvegardé avec chaque fichier .blend que Blender écrit. A partir de là, chaque fois que Blender charge un fichier .blend, il compare le SDNA du fichier .blend avec le SDNA lié à la version actuelle au moment de l’exécution, et utilise un code de sérialisation générique pour gérer toute différence. Cette stratégie donne à Blender un degré impressionnant de compatibilité ascendante et descendante. Vous pouvez toujours charger les fichiers 1.0 dans la dernière version de Blender, et les nouveaux .blendfichiers peuvent être chargés dans les anciennes versions.
Comme Blender, de nombreux moteurs de jeux – et leurs outils associés – génèrent et utilisent leurs propres données de réflexion. Il y a plusieurs façons de le faire : Vous pouvez analyser votre propre code source C/C++ pour extraire les informations de type, comme le fait Blender. Vous pouvez créer un langage de description de données séparé, et écrire un outil pour générer des définitions de types C++ et des données de réflexion à partir de ce langage. Vous pouvez utiliser des macros de préprocesseur et des modèles C++ pour générer des données de réflexion au moment de l’exécution. Et une fois que vous avez des données de réflexion disponibles, il y a d’innombrables façons d’écrire un sérialiseur générique par-dessus.
Certes, j’omets beaucoup de détails. Dans ce post, je veux seulement montrer qu’il existe de nombreuses façons différentes de sérialiser des données, dont certaines sont très complexes. Les programmeurs ne discutent tout simplement pas de la sérialisation autant que les autres systèmes moteurs, même si la plupart des autres systèmes en dépendent. Par exemple, sur les 96 conférences de programmation données à la GDC 2017, j’ai compté 31 conférences sur les graphiques, 11 sur le online, 10 sur les outils, 4 sur l’IA, 3 sur la physique, 2 sur l’audio – mais une seule qui abordait directement la sérialisation.
Au minimum, essayez d’avoir une idée de la complexité de vos besoins. Si vous faites un tout petit jeu comme Flappy Bird, avec seulement quelques actifs, vous n’avez probablement pas besoin de penser trop fort à la sérialisation. Vous pouvez probablement charger des textures directement à partir de PNG et tout ira bien. Si vous avez besoin d’un format binaire compact avec une compatibilité descendante, mais que vous ne voulez pas développer votre propre format, jetez un coup d’œil aux bibliothèques tierces telles que Cereal ou Boost.Serialization. Je ne pense pas que les tampons de protocole Google soient idéaux pour sérialiser les actifs de jeu, mais ils valent néanmoins la peine d’être étudiés.
Écrire un moteur de jeu – même petit – est une grande entreprise. Il y a beaucoup plus que je pourrais dire à ce sujet, mais pour un post de cette longueur, c’est honnêtement le conseil le plus utile que je peux penser à donner : Travaillez de manière itérative, résistez à l’envie d’unifier un peu le code et sachez que la sérialisation est un vaste sujet afin de pouvoir choisir une stratégie appropriée. D’après mon expérience, chacune de ces choses peut devenir une pierre d’achoppement si elle est ignorée.
J’adore comparer les notes sur ce genre de choses, donc je serais vraiment intéressé d’entendre d’autres développeurs. Si vous avez écrit un moteur, votre expérience vous a-t-elle conduit à l’une des mêmes conclusions ? Et si vous n’en avez pas écrit un, ou si vous y songez, je suis également intéressé par vos réflexions. Que considérez-vous comme une bonne ressource pour apprendre ? Quelles sont les parties qui vous semblent encore mystérieuses ? N’hésitez pas à laisser un commentaire ci-dessous ou à me contacter sur Twitter!