Últimamente he estado escribiendo un motor de juegos en C++. Lo estoy usando para hacer un pequeño juego para móviles llamado Hop Out. Aquí hay un clip capturado desde mi iPhone 6. (¡Desactiva el sonido!)

Hop Out es el tipo de juego que quiero hacer: Juego de arcade retro con un aspecto de dibujos animados en 3D. El objetivo es cambiar el color de cada almohadilla, como en Q*Bert.
Hop Out todavía está en desarrollo, pero el motor que lo impulsa está empezando a ser bastante maduro, así que pensé en compartir algunos consejos sobre el desarrollo del motor aquí.
¿Por qué querrías escribir un motor de juego? Hay muchas razones posibles:
- Eres un manitas. Te encanta construir sistemas desde cero y ver cómo cobran vida.
- Quieres aprender más sobre el desarrollo de juegos. Pasé 14 años en la industria de los juegos y todavía estoy descubriéndolo. Ni siquiera estaba seguro de poder escribir un motor desde cero, ya que es muy diferente a las responsabilidades diarias de un trabajo de programación en un gran estudio. Quería averiguarlo.
- Te gusta el control. Es satisfactorio organizar el código exactamente como quieres, sabiendo dónde está todo en todo momento.
- Te sientes inspirado por motores de juego clásicos como AGI (1984), id Tech 1 (1993), Build (1995), y gigantes de la industria como Unity y Unreal.
- Crees que nosotros, la industria del juego, deberíamos intentar desmitificar el proceso de desarrollo de motores. No es que hayamos dominado el arte de hacer juegos. Ni mucho menos. Cuanto más examinemos este proceso, más posibilidades tendremos de mejorarlo.
Las plataformas de juego de 2017 -móviles, consolas y PC- son muy potentes y, en muchos aspectos, bastante similares entre sí. El desarrollo de motores de juego no consiste tanto en luchar con un hardware débil y exótico, como ocurría en el pasado. En mi opinión, se trata más bien de luchar con la complejidad que tú mismo creas. Es fácil crear un monstruo. Por eso los consejos de este post se centran en mantener las cosas manejables. Lo he organizado en tres secciones:
- Usa un enfoque iterativo
- Piénsalo dos veces antes de unificar demasiado las cosas
- Sé consciente de que la serialización es un gran tema
Este consejo se aplica a cualquier tipo de motor de juego. No voy a decirte cómo escribir un shader, qué es un octree o cómo añadir física. Esos son los tipos de cosas que, asumo, ya sabes que deberías saber – y depende en gran medida del tipo de juego que quieras hacer. En su lugar, he elegido deliberadamente puntos que no parecen ser ampliamente reconocidos o hablados – estos son los tipos de puntos que encuentro más interesantes cuando se trata de desmitificar un tema.
Usa un enfoque iterativo
Mi primer consejo es conseguir algo (¡cualquier cosa!) que se ejecute rápidamente, y luego iterar.
Si es posible, comienza con una aplicación de ejemplo que inicialice el dispositivo y dibuje algo en la pantalla. En mi caso, descargué SDL, abrí Xcode-iOS/Test/TestiPhoneOS.xcodeproj y luego ejecuté la muestra testgles2 en mi iPhone.

¡Voilà! Tenía un encantador cubo girando usando OpenGL ES 2.0.
Mi siguiente paso fue descargar un modelo 3D que alguien hizo de Mario. Escribí un rápido y sucio cargador de archivos OBJ -el formato de los archivos no es tan complicado- y hackeé la aplicación de ejemplo para renderizar a Mario en lugar de un cubo. También integré SDL_Image para ayudar a cargar las texturas.

Luego implementé controles de doble palanca para mover a Mario. (Al principio, estaba contemplando hacer un shooter de doble stick. Pero no con Mario).

Luego, quise explorar la animación esquelética, así que abrí Blender, modelé un tentáculo y lo equipé con un esqueleto de dos huesos que se movía hacia adelante y hacia atrás.
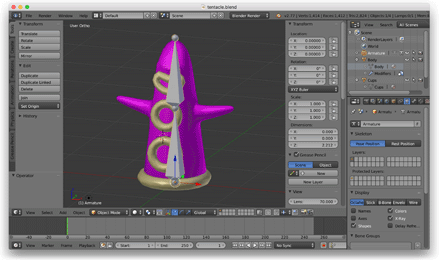
En este punto, abandoné el formato de archivo OBJ y escribí un script en Python para exportar archivos JSON personalizados desde Blender. Estos archivos JSON describían la malla con piel, el esqueleto y los datos de animación. Cargué estos archivos en el juego con la ayuda de una biblioteca JSON de C++.

Una vez que eso funcionó, volví a Blender e hice un personaje más elaborado. (Este fue el primer humano 3D rigged que he creado. Estaba bastante orgulloso de él.)

Durante los siguientes meses, di los siguientes pasos:
- Empecé a factorizar funciones vectoriales y matriciales en mi propia biblioteca matemática 3D.
- Cambié el
.xcodeprojpor un proyecto CMake. - Conseguí que el motor funcionara tanto en Windows como en iOS, porque me gusta trabajar en Visual Studio.
- Empecé a mover el código en bibliotecas separadas de «motor» y «juego». Con el tiempo, los dividí en bibliotecas aún más granulares.
- Escribí una aplicación separada para convertir mis archivos JSON en datos binarios que el juego puede cargar directamente.
- Finalmente eliminé todas las bibliotecas SDL de la construcción de iOS. (La construcción de Windows todavía utiliza SDL.)
El punto es: No planeé la arquitectura del motor antes de empezar a programar. Esta fue una elección deliberada. En lugar de eso, me limité a escribir el código más sencillo que implementaba la siguiente característica, y luego miraba el código para ver qué tipo de arquitectura surgía de forma natural. Por «arquitectura del motor», me refiero al conjunto de módulos que componen el motor del juego, las dependencias entre esos módulos y la API para interactuar con cada módulo.
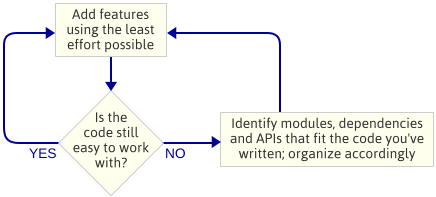
Este es un enfoque iterativo porque se centra en entregas más pequeñas. Funciona bien cuando se escribe un motor de juego porque, en cada paso del camino, se tiene un programa en ejecución. Si algo va mal cuando estás introduciendo código en un nuevo módulo, siempre puedes comparar tus cambios con el código que funcionaba anteriormente. Obviamente, asumo que estás usando algún tipo de control de código fuente.
Podrías pensar que se pierde mucho tiempo con este enfoque, ya que siempre estás escribiendo código malo que necesita ser limpiado más tarde. Pero la mayor parte de la limpieza consiste en mover el código de un archivo .cpp a otro, extraer declaraciones de funciones en archivos .h, o cambios igualmente sencillos. Decidir dónde deben ir las cosas es la parte difícil, y eso es más fácil de hacer cuando el código ya existe.
Yo diría que se pierde más tiempo en el enfoque opuesto: Tratar de idear una arquitectura que haga todo lo que crees que vas a necesitar antes de tiempo. Dos de mis artículos favoritos sobre los peligros del exceso de ingeniería son The Vicious Circle of Generalization (El círculo vicioso de la generalización), de Tomasz Dąbrowski, y Don’t Let Architecture Astronauts Scare You (No dejes que los astronautas de la arquitectura te asusten), de Joel Spolsky.
No estoy diciendo que nunca debas resolver un problema sobre el papel antes de abordarlo en el código. Tampoco estoy diciendo que no debas decidir qué características quieres de antemano. Por ejemplo, yo sabía desde el principio que quería que mi motor cargara todos los activos en un hilo de fondo. Simplemente no traté de diseñar o implementar esa característica hasta que mi motor realmente cargó algunos activos primero.
El enfoque iterativo me ha dado una arquitectura mucho más elegante de lo que jamás podría haber soñado mirando una hoja de papel en blanco. La construcción de iOS de mi motor es ahora 100% código original, incluyendo una biblioteca matemática personalizada, plantillas de contenedores, sistema de reflexión/serialización, marco de renderizado, física y mezclador de audio. Tenía razones para escribir cada uno de esos módulos, pero puede que no encuentres necesario escribir todas esas cosas tú mismo. Hay un montón de grandes bibliotecas de código abierto, con licencia permisiva, que podría encontrar apropiado para su motor en su lugar. GLM, Bullet Physics y las cabeceras STB son sólo algunos ejemplos interesantes.
Piensa dos veces antes de unificar demasiado las cosas
Como programadores, tratamos de evitar la duplicación de código, y nos gusta cuando nuestro código sigue un estilo uniforme. Sin embargo, creo que es bueno no dejar que esos instintos anulen cada decisión.
Responde al principio DRY de vez en cuando
Para darte un ejemplo, mi motor contiene varias clases de plantillas de «punteros inteligentes», similares en espíritu a std::shared_ptr. Cada uno ayuda a prevenir las fugas de memoria sirviendo como una envoltura alrededor de un puntero crudo.
-
Owned<>es para los objetos asignados dinámicamente que tienen un solo propietario. -
Reference<>utiliza el conteo de referencias para permitir que un objeto tenga varios propietarios. -
audio::AppOwned<>es utilizado por el código fuera del mezclador de audio. Permite que los sistemas de juego posean objetos que el mezclador de audio utiliza, como una voz que se está reproduciendo en ese momento. -
audio::AudioHandle<>utiliza un sistema de conteo de referencias interno al mezclador de audio.
Puede parecer que algunas de esas clases duplican la funcionalidad de las otras, violando el principio DRY (Don’t Repeat Yourself). De hecho, al principio del desarrollo, traté de reutilizar la clase Reference<> existente tanto como fuera posible. Sin embargo, descubrí que el tiempo de vida de un objeto de audio se rige por reglas especiales: Si una voz de audio ha terminado de reproducir una muestra, y el juego no mantiene un puntero a esa voz, la voz puede ser puesta en cola para ser eliminada inmediatamente. Si el juego tiene un puntero, entonces el objeto de voz no debe ser borrado. Y si el juego mantiene un puntero, pero el dueño del puntero es destruido antes de que la voz haya terminado, la voz debe ser cancelada. En lugar de añadir complejidad a Reference<>, decidí que era más práctico introducir clases de plantilla separadas en su lugar.
El 95% de las veces, reutilizar el código existente es el camino a seguir. Pero si empiezas a sentirte paralizado, o te encuentras añadiendo complejidad a algo que antes era simple, pregúntate si algo en la base de código debería ser realmente dos cosas.
Está bien usar diferentes convenciones de llamada
Una cosa que no me gusta de Java es que te obliga a definir cada función dentro de una clase. Eso no tiene sentido, en mi opinión. Puede hacer que tu código parezca más consistente, pero también fomenta el exceso de ingeniería y no se presta bien al enfoque iterativo que he descrito antes.
En mi motor C++, algunas funciones pertenecen a clases y otras no. Por ejemplo, cada enemigo en el juego es una clase, y la mayor parte del comportamiento del enemigo se implementa dentro de esa clase, como probablemente esperarías. Por otro lado, los cambios de esfera en mi motor se realizan llamando a sphereCast(), una función en el espacio de nombres physics. sphereCast() no pertenece a ninguna clase – sólo es parte del módulo physics. Tengo un sistema de construcción que gestiona las dependencias entre módulos, lo que mantiene el código organizado lo suficientemente bien para mí. Envolver esta función dentro de una clase arbitraria no mejorará la organización del código de ninguna manera significativa.
Luego está el envío dinámico, que es una forma de polimorfismo. A menudo necesitamos llamar a una función para un objeto sin saber el tipo exacto de ese objeto. El primer instinto de un programador de C++ es definir una clase base abstracta con funciones virtuales, y luego anular esas funciones en una clase derivada. Eso es válido, pero es sólo una técnica. Hay otras técnicas de envío dinámico que no introducen tanto código extra, o que aportan otros beneficios:
- C++11 introdujo
std::function, que es una forma conveniente de almacenar funciones de devolución de llamada. También es posible escribir su propia versión destd::functionque es menos doloroso para entrar en el depurador. - Muchas funciones de devolución de llamada se puede implementar con un par de punteros: Un puntero a la función y un argumento opaco. Sólo requiere un casting explícito dentro de la función callback. Esto se ve mucho en las bibliotecas de C puro.
- A veces, el tipo subyacente se conoce en tiempo de compilación, y se puede enlazar la llamada a la función sin ninguna sobrecarga adicional en tiempo de ejecución. Turf, una biblioteca que uso en mi motor de juego, se basa en esta técnica mucho. Ver
turf::Mutexpor ejemplo. Es sólo untypedefsobre una clase específica de la plataforma. - A veces, el enfoque más directo es construir y mantener una tabla de punteros de función en bruto usted mismo. He utilizado este enfoque en mi mezclador de audio y sistema de serialización. El intérprete de Python también hace un gran uso de esta técnica, como se menciona a continuación.
- Incluso puedes almacenar los punteros de las funciones en una tabla hash, utilizando los nombres de las funciones como claves. Utilizo esta técnica para enviar eventos de entrada, como los eventos multitáctiles. Es parte de una estrategia para grabar las entradas del juego y reproducirlas con un sistema de repetición.
El envío dinámico es un gran tema. Sólo estoy rascando la superficie para mostrar que hay muchas maneras de lograrlo. Cuanto más escribas código extensible de bajo nivel – lo cual es común en un motor de juegos – más te encontrarás explorando alternativas. Si no estás acostumbrado a este tipo de programación, el intérprete de Python, que está escrito en C, es un excelente recurso para aprender. Implementa un potente modelo de objetos: Cada PyObject apunta a un PyTypeObject, y cada PyTypeObject contiene una tabla de punteros a funciones para su envío dinámico. El documento Definición de nuevos tipos es un buen punto de partida si quieres saltar directamente.
Sé consciente de que la serialización es un gran tema
La serialización es el acto de convertir objetos en tiempo de ejecución a y desde una secuencia de bytes. En otras palabras, guardar y cargar datos.
Para muchos, si no la mayoría, de los motores de juego, el contenido del juego se crea en varios formatos editables como .png, .json, .blend o formatos propietarios, y luego se convierte finalmente en formatos de juego específicos de la plataforma que el motor puede cargar rápidamente. La última aplicación de este proceso suele denominarse «cocinador». El cocinero puede estar integrado en otra herramienta, o incluso distribuido en varias máquinas. Normalmente, el cooker y una serie de herramientas se desarrollan y mantienen junto con el propio motor del juego.
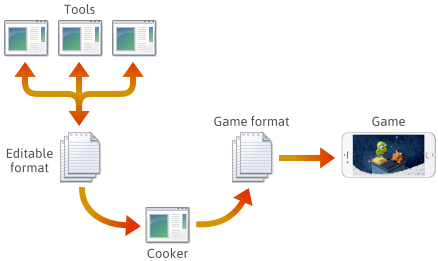
Cuando se configura un pipeline de este tipo, la elección del formato de archivo en cada etapa depende de ti. Puedes definir algunos formatos de archivo propios, y esos formatos pueden evolucionar a medida que agregas características al motor. A medida que evolucionen, es posible que encuentres necesario mantener ciertos programas compatibles con los archivos guardados anteriormente. No importa el formato, al final necesitarás serializarlo en C++.
Hay innumerables maneras de implementar la serialización en C++. Una forma bastante obvia es añadir funciones load y save a las clases de C++ que desea serializar. Usted puede lograr la compatibilidad hacia atrás mediante el almacenamiento de un número de versión en la cabecera del archivo, a continuación, pasar este número en cada función load. Esto funciona, aunque el código puede llegar a ser engorroso de mantener.
void load(InStream& in, u32 fileVersion) { // Load expected member variables in >> m_position; in >> m_direction; // Load a newer variable only if the file version being loaded is 2 or greater if (fileVersion >= 2) { in >> m_velocity; } }
Es posible escribir un código de serialización más flexible y menos propenso a errores aprovechando la reflexión – específicamente, creando datos en tiempo de ejecución que describan la disposición de sus tipos C++. Para una rápida idea de cómo la reflexión puede ayudar con la serialización, echa un vistazo a cómo Blender, un proyecto de código abierto, lo hace.
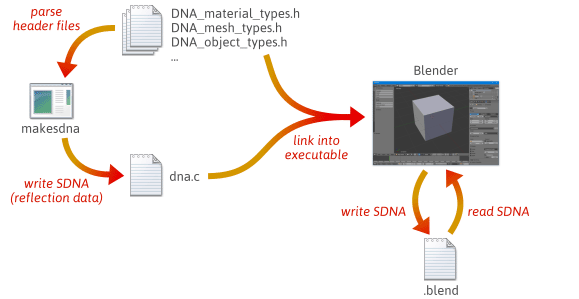
Cuando se construye Blender desde el código fuente, ocurren muchos pasos. Primero, se compila y ejecuta una utilidad personalizada llamada makesdna. Esta utilidad analiza un conjunto de archivos de cabecera C en el árbol de código fuente de Blender, y luego produce un resumen compacto de todos los tipos C definidos dentro, en un formato personalizado conocido como SDNA. Estos datos SDNA sirven como datos de reflexión. El SDNA es entonces enlazado en el propio Blender, y guardado con cada archivo .blend que Blender escribe. A partir de ese momento, cada vez que Blender carga un archivo .blend, compara el SDNA del archivo .blend con el SDNA vinculado a la versión actual en tiempo de ejecución, y utiliza código de serialización genérico para manejar cualquier diferencia. Esta estrategia da a Blender un impresionante grado de compatibilidad hacia atrás y hacia adelante. Usted todavía puede cargar archivos 1.0 en la última versión de Blender, y los nuevos .blend archivos pueden ser cargados en versiones anteriores.
Al igual que Blender, muchos motores de juegos – y sus herramientas asociadas – generan y utilizan sus propios datos de reflexión. Hay muchas maneras de hacerlo: Puedes analizar tu propio código fuente C/C++ para extraer la información de tipo, como hace Blender. Puedes crear un lenguaje de descripción de datos separado, y escribir una herramienta para generar definiciones de tipo C++ y datos de reflexión desde este lenguaje. Puede utilizar macros de preprocesador y plantillas de C++ para generar datos de reflexión en tiempo de ejecución. Y una vez que tengas los datos de reflexión disponibles, hay innumerables formas de escribir un serializador genérico sobre ellos.
Está claro que estoy omitiendo muchos detalles. En este post, sólo quiero mostrar que hay muchas formas diferentes de serializar datos, algunas de las cuales son muy complejas. Los programadores simplemente no discuten la serialización tanto como otros sistemas de motor, a pesar de que la mayoría de los otros sistemas dependen de ella. Por ejemplo, de las 96 charlas de programación que se dieron en la GDC 2017, conté 31 charlas sobre gráficos, 11 sobre online, 10 sobre herramientas, 4 sobre IA, 3 sobre física, 2 sobre audio – pero solo una que tocó directamente la serialización.
Como mínimo, intenta tener una idea de lo complejas que serán tus necesidades. Si estás haciendo un pequeño juego como Flappy Bird, con sólo unos pocos activos, probablemente no necesitas pensar demasiado en la serialización. Probablemente puedas cargar las texturas directamente desde PNG y estará bien. Si necesitas un formato binario compacto con compatibilidad hacia atrás, pero no quieres desarrollar el tuyo propio, echa un vistazo a las bibliotecas de terceros como Cereal o Boost.Serialization. No creo que los Google Protocol Buffers sean ideales para serializar los activos de los juegos, pero de todos modos vale la pena estudiarlos.
Escribir un motor de juegos – incluso uno pequeño – es una gran empresa. Hay mucho más que podría decir al respecto, pero para un post de esta longitud, ese es honestamente el consejo más útil que se me ocurre dar: Trabajar de forma iterativa, resistir el impulso de unificar un poco el código, y saber que la serialización es un gran tema para poder elegir una estrategia adecuada. En mi experiencia, cada una de esas cosas puede convertirse en un escollo si se ignora.
Me encanta comparar notas sobre estas cosas, así que me interesaría mucho escuchar a otros desarrolladores. Si has escrito un motor, ¿tu experiencia te llevó a alguna de las mismas conclusiones? Y si no has escrito uno, o sólo estás pensando en ello, también me interesan tus opiniones. ¿Qué consideras un buen recurso para aprender? ¿Qué partes te siguen pareciendo misteriosas? No dudes en dejar un comentario a continuación o en escribirme en Twitter
.