Ostatnio pisałem silnik gry w C++. Używam go do stworzenia małej gry mobilnej o nazwie Hop Out. Oto klip nagrany z mojego iPhone’a 6. (Wycisz dla dźwięku!)

Hop Out jest rodzajem gry, w którą chcę grać: Retro arcade gameplay z kreskówkowym wyglądem 3D. Celem jest zmiana koloru każdego klocka, jak w Q*Bert.
Hop Out jest wciąż w fazie rozwoju, ale silnik, który go napędza, zaczyna być całkiem dojrzały, więc pomyślałem, że podzielę się tutaj kilkoma wskazówkami na temat rozwoju silnika.
Dlaczego chciałbyś napisać silnik gry? Jest wiele możliwych powodów:
- Jesteś majsterkowiczem. Uwielbiasz budować systemy od podstaw i patrzeć, jak ożywają.
- Chcesz dowiedzieć się więcej o tworzeniu gier. Spędziłem 14 lat w branży gier i nadal się w niej orientuję. Nie byłem nawet pewien, czy potrafiłbym napisać silnik od podstaw, ponieważ jest to coś zupełnie innego niż codzienne obowiązki programisty w dużym studiu. Chciałem się przekonać.
- Lubisz kontrolę. Satysfakcjonujące jest organizowanie kodu dokładnie tak, jak chcesz, wiedząc, gdzie wszystko jest przez cały czas.
- Czujesz inspirację klasycznymi silnikami gier, takimi jak AGI (1984), id Tech 1 (1993), Build (1995) i gigantami branży, takimi jak Unity i Unreal.
- Wierzysz, że my, przemysł gier, powinniśmy spróbować zdemistyfikować proces tworzenia silnika. To nie jest tak, że opanowaliśmy sztukę tworzenia gier. Daleko od tego! Im bardziej zbadamy ten proces, tym większe mamy szanse na jego udoskonalenie.
Platformy do gier z 2017 roku – mobilna, konsolowa i PC – są bardzo potężne i pod wieloma względami dość podobne do siebie. Tworzenie silników gier nie polega już tak bardzo na zmaganiu się ze słabym i egzotycznym sprzętem, jak to było w przeszłości. Moim zdaniem, chodzi raczej o zmaganie się z własną złożonością. Łatwo jest stworzyć potwora! Dlatego też porady w tym poście koncentrują się wokół utrzymania rzeczy w ryzach. Zorganizowałem je w trzy sekcje:
- Używaj podejścia iteracyjnego
- Zastanów się dwa razy, zanim zbytnio zunifikujesz rzeczy
- Bądź świadomy, że serializacja to duży temat
Ta rada dotyczy każdego rodzaju silnika gry. Nie zamierzam ci mówić jak napisać shader, co to jest octree, czy jak dodać fizykę. To są rzeczy, które, jak zakładam, już wiesz, że powinieneś wiedzieć – i zależy to w dużej mierze od rodzaju gry, którą chcesz stworzyć. Zamiast tego, celowo wybrałem punkty, które nie wydają się być powszechnie znane lub o których się nie mówi – są to rodzaje punktów, które uważam za najbardziej interesujące, gdy próbuję zdemistyfikować temat.
Use an Iterative Approach
Moją pierwszą radą jest uruchomienie czegoś (czegokolwiek!) szybko, a następnie iteracja.
Jeśli to możliwe, zacznij od przykładowej aplikacji, która inicjalizuje urządzenie i rysuje coś na ekranie. W moim przypadku pobrałem SDL, otworzyłem Xcode-iOS/Test/TestiPhoneOS.xcodeproj, a następnie uruchomiłem próbkę testgles2 na moim iPhonie.

Voilà! Miałem piękny wirujący sześcian używający OpenGL ES 2.0.
Moim następnym krokiem było ściągnięcie modelu 3D, który ktoś zrobił z Mario. Napisałem szybki & brudny loader plików OBJ – format plików nie jest aż tak skomplikowany – i zhakowałem przykładową aplikację, aby renderowała Mario zamiast sześcianu. Zintegrowałem również SDL_Image, aby ułatwić ładowanie tekstur.

Potem zaimplementowałem sterowanie dwoma drążkami, aby poruszać Mario. (Na początku zastanawiałem się nad zrobieniem strzelanki z dwoma drążkami. Ale nie z Mario.)

Następnie chciałem zbadać animację szkieletową, więc otworzyłem Blendera, wymodelowałem mackę i wyposażyłem ją w dwukostkowy szkielet, który poruszał się w przód i w tył.
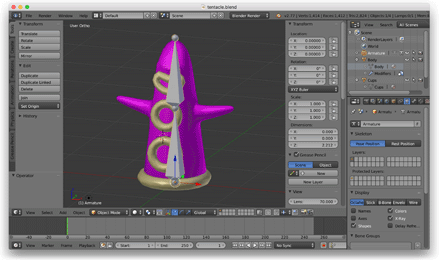
W tym momencie porzuciłem format plików OBJ i napisałem skrypt Pythona do eksportowania niestandardowych plików JSON z Blendera. Te pliki JSON opisywały siatkę, szkielet i dane animacji. Pliki te wczytałem do gry za pomocą biblioteki JSON w C++.

Gdy to zadziałało, wróciłem do Blendera i stworzyłem bardziej rozbudowaną postać. (To był pierwszy rigowany człowiek 3D, jakiego kiedykolwiek stworzyłem. Byłem z niego całkiem dumny.)

W ciągu następnych kilku miesięcy podjąłem następujące kroki:
- Zacząłem faktoryzować funkcje wektorowe i macierzowe w mojej własnej bibliotece matematycznej 3D.
- Zastąpiłem
.xcodeprojprojektem CMake. - Gotowałem silnik działający zarówno na Windowsie jak i iOS, ponieważ lubię pracować w Visual Studio.
- Zacząłem przenosić kod do oddzielnych bibliotek „silnika” i „gry”. Z czasem podzieliłem je na jeszcze bardziej granularne biblioteki.
- Napisałem osobną aplikację do konwersji moich plików JSON na dane binarne, które gra może załadować bezpośrednio.
- W końcu usunąłem wszystkie biblioteki SDL z kompilacji dla iOS. (Wersja dla Windows nadal używa SDL.)
Chodzi o to, że: Nie planowałem architektury silnika, zanim zacząłem programować. To był celowy wybór. Zamiast tego, po prostu pisałem najprostszy kod, który implementował następną funkcjonalność, a potem patrzyłem na kod, aby zobaczyć, jaki rodzaj architektury wyłonił się naturalnie. Przez „architekturę silnika” rozumiem zestaw modułów, które składają się na silnik gry, zależności pomiędzy tymi modułami oraz API do interakcji z każdym modułem.
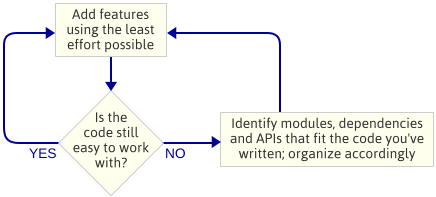
Jest to podejście iteracyjne, ponieważ skupia się na mniejszych produktach. Sprawdza się to podczas pisania silnika gry, ponieważ na każdym kroku po drodze masz działający program. Jeśli coś pójdzie nie tak podczas tworzenia nowego modułu, zawsze możesz porównać swoje zmiany z kodem, który działał wcześniej. Oczywiście, zakładam, że używasz jakiegoś rodzaju kontroli źródła.
Możesz pomyśleć, że w tym podejściu marnuje się dużo czasu, ponieważ zawsze piszesz zły kod, który trzeba później posprzątać. Ale większość sprzątania polega na przenoszeniu kodu z jednego pliku .cpp do drugiego, wyodrębnianiu deklaracji funkcji do plików .h lub równie prostych zmian. Podjęcie decyzji, gdzie rzeczy powinny trafić, jest trudną częścią, a to jest łatwiejsze do zrobienia, gdy kod już istnieje.
Twierdziłbym, że więcej czasu marnuje się przy odwrotnym podejściu: Próbując zbyt mocno, aby wymyślić architekturę, która zrobi wszystko, co myślisz, że będziesz potrzebował z wyprzedzeniem. Dwa z moich ulubionych artykułów na temat niebezpieczeństw związanych z nadmierną inżynierią to The Vicious Circle of Generalization Tomasza Dąbrowskiego i Don’t Let Architecture Astronauts Scare You Joela Spolsky’ego.
Nie twierdzę, że nigdy nie powinieneś rozwiązywać problemu na papierze, zanim zajmiesz się nim w kodzie. Nie mówię też, że nie powinieneś decydować, jakie funkcje chcesz mieć z wyprzedzeniem. Na przykład, od początku wiedziałem, że chcę, aby mój silnik ładował wszystkie zasoby w wątku tła. Po prostu nie próbowałem projektować ani implementować tej funkcji, dopóki mój silnik nie załadował najpierw niektórych zasobów.
Podejście iteracyjne dało mi dużo bardziej elegancką architekturę, niż kiedykolwiek mogłem sobie wymarzyć, wpatrując się w pustą kartkę papieru. Konstrukcja mojego silnika na iOS to teraz w 100% oryginalny kod zawierający niestandardową bibliotekę matematyczną, szablony kontenerów, system refleksji/serializacji, szkielet renderowania, fizykę i mikser audio. Miałem powody do napisania każdego z tych modułów, ale może się okazać, że nie jest konieczne pisanie wszystkich tych rzeczy samemu. Istnieje wiele świetnych, licencjonowanych bibliotek open source, które mogą okazać się odpowiednie dla twojego silnika. GLM, Bullet Physics i nagłówki STB to tylko kilka interesujących przykładów.
Think Twice Before Unifying Things Too Much
Jako programiści staramy się unikać powielania kodu i lubimy, gdy nasz kod podąża za jednolitym stylem. Myślę jednak, że dobrze jest nie pozwolić, aby te instynkty wzięły górę nad każdą decyzją.
Resist the DRY Principle Once in a While
Aby dać ci przykład, mój silnik zawiera kilka klas szablonów „smart pointer”, podobnych w duchu do std::shared_ptr. Każda z nich pomaga zapobiegać wyciekom pamięci, służąc jako opakowanie wokół surowego wskaźnika.
-
Owned<>jest dla dynamicznie przydzielanych obiektów, które mają jednego właściciela. -
Reference<>używa liczenia referencji, aby umożliwić obiektowi posiadanie kilku właścicieli. -
audio::AppOwned<>jest używany przez kod poza mikserem audio. Pozwala systemom gier na posiadanie obiektów, których używa mikser audio, takich jak głos, który jest aktualnie odtwarzany. -
audio::AudioHandle<>używa systemu liczenia referencji wewnątrz miksera audio.
Może wyglądać na to, że niektóre z tych klas powielają funkcjonalność innych, naruszając zasadę DRY (Don’t Repeat Yourself). Rzeczywiście, na początku pracy nad projektem, próbowałem ponownie wykorzystać istniejącą klasę Reference<> tak bardzo jak to tylko możliwe. Odkryłem jednak, że czas życia obiektu audio rządzi się specjalnymi prawami: Jeśli głos audio zakończył odtwarzanie próbki, a gra nie trzyma wskaźnika do tego głosu, głos może zostać ustawiony w kolejce do natychmiastowego usunięcia. Jeżeli gra posiada wskaźnik, to obiekt głosu nie powinien być usuwany. A jeśli gra trzyma wskaźnik, ale właściciel wskaźnika zostanie zniszczony przed zakończeniem głosu, to głos powinien zostać anulowany. Zamiast dodawać złożoność do Reference<>, zdecydowałem, że praktyczniej będzie zamiast tego wprowadzić oddzielne klasy szablonów.
95% czasu, ponowne wykorzystanie istniejącego kodu jest drogą do zrobienia. Ale jeśli zaczynasz czuć się sparaliżowany lub zauważasz, że dodajesz złożoność do czegoś, co kiedyś było proste, zadaj sobie pytanie, czy coś w bazie danych powinno być dwoma rzeczami.
It’s OK to Use Different Calling Conventions
Jedną z rzeczy, których nie lubię w Javie, jest to, że zmusza cię ona do definiowania każdej funkcji wewnątrz klasy. To nonsens, moim zdaniem. Może dzięki temu twój kod wygląda bardziej spójnie, ale zachęca do nadmiernej inżynierii i nie nadaje się dobrze do iteracyjnego podejścia, które opisałem wcześniej.
W moim silniku C++ niektóre funkcje należą do klas, a niektóre nie. Na przykład, każdy wróg w grze jest klasą i większość jego zachowań jest zaimplementowana wewnątrz tej klasy, jak się pewnie spodziewasz. Z drugiej strony, rzutowanie na sferę w moim silniku jest wykonywane przez wywołanie sphereCast(), funkcji w przestrzeni nazw physics. sphereCast() nie należy do żadnej klasy – jest po prostu częścią modułu physics. Mam system kompilacji, który zarządza zależnościami między modułami, dzięki czemu kod jest dla mnie wystarczająco dobrze zorganizowany. Zawijanie tej funkcji w dowolną klasę nie poprawi organizacji kodu w żaden znaczący sposób.
Następnie mamy dynamiczną wysyłkę, która jest formą polimorfizmu. Często musimy wywołać funkcję dla jakiegoś obiektu, nie znając dokładnie jego typu. Pierwszym odruchem programisty C++ jest zdefiniowanie abstrakcyjnej klasy bazowej z funkcjami wirtualnymi, a następnie nadpisanie tych funkcji w klasie pochodnej. Jest to słuszne, ale jest to tylko jedna z technik. Istnieją inne techniki dynamicznej wysyłki, które nie wprowadzają tak dużo dodatkowego kodu lub przynoszą inne korzyści:
- C++11 wprowadził
std::function, który jest wygodnym sposobem przechowywania funkcji wywołania zwrotnego. Możliwe jest również napisanie własnej wersjistd::function, która jest mniej bolesna do wdepnięcia w debuggerze. - Wiele funkcji wywołania zwrotnego można zaimplementować za pomocą pary wskaźników: Wskaźnika funkcji i nieprzezroczystego argumentu. Wymaga to tylko jawnej obsady wewnątrz funkcji wywołania zwrotnego. Widzisz to dużo w czystych bibliotekach C.
- Czasami typ bazowy jest faktycznie znany w czasie kompilacji i możesz powiązać wywołanie funkcji bez dodatkowego narzutu runtime. Turf, biblioteka, której używam w moim silniku gry, polega na tej technice bardzo często. Zobacz
turf::Mutexna przykład. Jest to po prostutypedefnad klasą specyficzną dla platformy. - Czasami najprostszym podejściem jest samodzielne zbudowanie i utrzymanie tablicy surowych wskaźników funkcji. Użyłem tego podejścia w moim mikserze audio i systemie serializacji. Interpreter Pythona również intensywnie korzysta z tej techniki, jak wspomniano poniżej.
- Możesz nawet przechowywać wskaźniki funkcji w tablicy hash, używając nazw funkcji jako kluczy. Używam tej techniki do wysyłania zdarzeń wejściowych, takich jak zdarzenia multitouch. Jest to część strategii rejestrowania danych wejściowych w grze i odtwarzania ich za pomocą systemu powtórek.
Dynamiczne wysyłanie to duży temat. Ja tylko zarysowuję powierzchnię, aby pokazać, że istnieje wiele sposobów, aby to osiągnąć. Im więcej piszesz rozszerzalnego kodu niskiego poziomu – co jest częste w silnikach gier – tym więcej będziesz odkrywał alternatywnych rozwiązań. Jeśli nie jesteś przyzwyczajony do tego rodzaju programowania, interpreter Pythona, który jest napisany w języku C, jest doskonałym źródłem do nauki. Implementuje on potężny model obiektowy: Każdy PyObject wskazuje na PyTypeObject, a każdy PyTypeObject zawiera tablicę wskaźników funkcji do dynamicznej wysyłki. Dokument Definiowanie nowych typów jest dobrym punktem wyjścia, jeśli chcesz od razu wskoczyć do środka.
Be Aware that Serialization Is a Big Subject
Serializacja jest aktem konwersji obiektów runtime do i z sekwencji bajtów. Innymi słowy, zapisywanie i ładowanie danych.
W przypadku wielu, jeśli nie większości silników gier, zawartość gry jest tworzona w różnych edytowalnych formatach, takich jak .png, .json, .blend lub formatach zastrzeżonych, a następnie ostatecznie konwertowana do formatów gier specyficznych dla danej platformy, które silnik może szybko załadować. Ostatnia aplikacja w tym potoku jest często określana jako „cooker”. Może on być zintegrowany z innym narzędziem, lub nawet rozproszony na kilka maszyn. Zazwyczaj cooker i kilka narzędzi są rozwijane i utrzymywane razem z samym silnikiem gry.
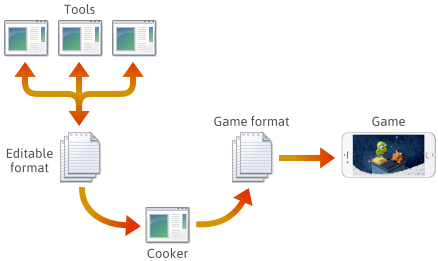
Przy tworzeniu takiego potoku, wybór formatu plików na każdym etapie zależy od Ciebie. Możesz zdefiniować kilka własnych formatów plików, a formaty te mogą ewoluować w miarę dodawania funkcji silnika. W miarę ich ewolucji może się okazać, że konieczne jest zachowanie zgodności niektórych programów z wcześniej zapisanymi plikami. Bez względu na format, ostatecznie będziesz musiał je serializować w C++.
Istnieją niezliczone sposoby implementacji serializacji w C++. Jednym z dość oczywistych sposobów jest dodanie funkcji load i save do klas C ++, które chcesz serializować. Kompatybilność wsteczną można osiągnąć poprzez przechowywanie numeru wersji w nagłówku pliku, a następnie przekazywanie tego numeru do każdej funkcji load. To działa, choć kod może stać się kłopotliwy w utrzymaniu.
void load(InStream& in, u32 fileVersion) { // Load expected member variables in >> m_position; in >> m_direction; // Load a newer variable only if the file version being loaded is 2 or greater if (fileVersion >= 2) { in >> m_velocity; } }
Możliwe jest napisanie bardziej elastycznego, mniej podatnego na błędy kodu serializacji poprzez wykorzystanie refleksji – a konkretnie poprzez stworzenie danych runtime, które opisują układ twoich typów C++. Aby szybko zorientować się, jak refleksja może pomóc w serializacji, spójrzmy jak robi to Blender, projekt open source.
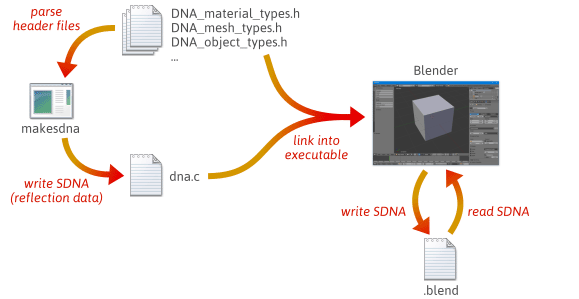
Kiedy budujesz Blendera z kodu źródłowego, dzieje się wiele kroków. Po pierwsze, narzędzie o nazwie makesdna jest kompilowane i uruchamiane. Narzędzie to przetwarza zestaw plików nagłówkowych C w drzewie źródłowym Blendera, a następnie wypisuje kompaktowe podsumowanie wszystkich zdefiniowanych w nich typów C, w niestandardowym formacie znanym jako SDNA. Te dane SDNA służą jako dane odbicia. SDNA jest następnie linkowane do samego Blendera i zapisywane z każdym .blend plikiem, który Blender napisze. Od tego momentu, za każdym razem gdy Blender ładuje plik .blend, porównuje SDNA pliku .blend z SDNA połączonym z aktualną wersją w trybie runtime, i używa ogólnego kodu serializacji do obsługi wszelkich różnic. Ta strategia daje Blenderowi imponujący stopień kompatybilności wstecz i w przód. Możesz nadal ładować pliki 1.0 w najnowszej wersji Blendera, a nowe .blend pliki mogą być ładowane w starszych wersjach.
Podobnie jak Blender, wiele silników gier – i związanych z nimi narzędzi – generuje i używa własnych danych odbicia. Istnieje wiele sposobów, aby to zrobić: Możesz parsować swój własny kod źródłowy C/C++, aby wydobyć informacje o typie, tak jak robi to Blender. Można stworzyć osobny język opisu danych i napisać narzędzie do generowania definicji typów C++ i danych odbicia z tego języka. Możesz użyć makr preprocesora i szablonów C++ do generowania danych refleksji w czasie wykonywania programu. A kiedy dane refleksji są już dostępne, istnieje niezliczona ilość sposobów na napisanie na ich podstawie ogólnego serializera.
Wyraźnie widać, że pomijam wiele szczegółów. W tym poście chcę tylko pokazać, że istnieje wiele różnych sposobów serializacji danych, z których niektóre są bardzo złożone. Programiści po prostu nie omawiają serializacji tak bardzo, jak innych systemów silnikowych, mimo że większość innych systemów na niej polega. Na przykład, spośród 96 rozmów programistycznych wygłoszonych na GDC 2017, naliczyłem 31 rozmów o grafice, 11 o online, 10 o narzędziach, 4 o AI, 3 o fizyce, 2 o audio – ale tylko jeden, który dotknął bezpośrednio serializacji.
Przynajmniej spróbuj mieć pomysł, jak złożone będą twoje potrzeby. Jeśli robisz malutką grę jak Flappy Bird, z tylko kilkoma aktywami, prawdopodobnie nie musisz myśleć zbyt ciężko o serializacji. Prawdopodobnie możesz załadować tekstury bezpośrednio z PNG i będzie dobrze. Jeśli potrzebujesz kompaktowego formatu binarnego z kompatybilnością wsteczną, ale nie chcesz tworzyć własnego, spójrz na biblioteki innych firm, takie jak Cereal lub Boost.Serialization. Nie sądzę, aby Google Protocol Buffers były idealne do serializacji zasobów gry, ale mimo to warto się z nimi zapoznać.
Pisanie silnika gry – nawet małego – jest dużym przedsięwzięciem. Jest wiele więcej rzeczy, które mógłbym powiedzieć na ten temat, ale jak na post tej długości, to szczerze mówiąc najbardziej pomocna rada, jaką mogę dać: Pracuj iteracyjnie, oprzyj się chęci ujednolicenia kodu trochę, i wiedz, że serializacja jest dużym tematem, abyś mógł wybrać odpowiednią strategię. Z mojego doświadczenia wynika, że każda z tych rzeczy może stać się przeszkodą, jeśli zostanie zignorowana.
Uwielbiam porównywać notatki na ten temat, więc byłbym bardzo zainteresowany wysłuchaniem innych programistów. Jeśli napisałeś już silnik, czy twoje doświadczenie doprowadziło cię do takich samych wniosków? A jeśli jeszcze nie napisałeś silnika, lub dopiero się nad tym zastanawiasz, również jestem ciekaw twoich przemyśleń. Co uważasz za dobre źródło wiedzy, z którego możesz się uczyć? Jakie części nadal wydają Ci się tajemnicze? Nie krępuj się zostawić komentarz poniżej lub uderz mnie na Twitterze!