De laatste tijd ben ik bezig geweest met het schrijven van een game engine in C++. Ik gebruik het om een klein mobiel spel te maken genaamd Hop Out. Hier is een filmpje, opgenomen met mijn iPhone 6. (Unmute voor geluid!)

Hop Out is het soort spel dat ik wil spelen: Retro arcadegameplay met een 3D-tekenfilmlook. Het doel is om de kleur van elke pad te veranderen, zoals in Q*Bert.
Hop Out is nog steeds in ontwikkeling, maar de engine die het aandrijft begint al aardig volwassen te worden, dus ik dacht dat ik hier een paar tips over engine-ontwikkeling zou kunnen delen.
Waarom zou je een game-engine willen schrijven? Er zijn veel mogelijke redenen:
- Je bent een knutselaar. Je houdt ervan systemen vanaf de grond op te bouwen en ze tot leven te zien komen.
- Je wilt meer leren over game-ontwikkeling. Ik heb 14 jaar in de game-industrie gezeten en ik ben het nog steeds aan het uitzoeken. Ik wist niet eens zeker of ik wel een engine kon schrijven, omdat het heel wat anders is dan de dagelijkse verantwoordelijkheden van een programmeerbaan bij een grote studio. Ik wilde het uitvinden.
- Je houdt van controle. Het geeft voldoening om de code precies zo in te richten als jij wilt, wetende waar alles is op elk moment.
- Je voelt je geïnspireerd door klassieke game engines zoals AGI (1984), id Tech 1 (1993), Build (1995), en industrie giganten zoals Unity en Unreal.
- Je gelooft dat wij, de game industrie, moeten proberen om het engine ontwikkelingsproces te demystificeren. Het is niet zo dat we de kunst van het spellen maken onder de knie hebben. Verre van dat! Hoe meer we dit proces onderzoeken, hoe groter onze kansen om het te verbeteren.
De gameplatforms van 2017 – mobiel, console en pc – zijn zeer krachtig en lijken in veel opzichten behoorlijk op elkaar. Game engine ontwikkeling gaat niet zozeer over het worstelen met zwakke en exotische hardware, zoals het in het verleden was. Naar mijn mening gaat het meer om het worstelen met complexiteit die je zelf hebt gemaakt. Het is gemakkelijk om een monster te creëren! Daarom is het advies in dit artikel gericht op het beheersbaar houden van de dingen. Ik heb het in drie secties onderverdeeld:
- Gebruik een iteratieve aanpak
- Denk twee keer na voordat u dingen te veel verenigt
- Ben u ervan bewust dat serialisatie een groot onderwerp is
Dit advies geldt voor elk soort game engine. Ik ga je niet vertellen hoe je een shader moet schrijven, wat een octree is, of hoe je physics moet toevoegen. Dat zijn het soort dingen waarvan ik aanneem dat je al weet dat je ze zou moeten weten – en het hangt grotendeels af van het type spel dat je wil maken. In plaats daarvan heb ik met opzet punten gekozen die niet algemeen erkend of besproken lijken te worden – dit zijn het soort punten die ik het meest interessant vind als ik een onderwerp probeer te demystifiëren.
Gebruik een Iteratieve Benadering
Mijn eerste advies is om snel iets (wat dan ook!) aan de praat te krijgen, en dan te itereren.
Indien mogelijk, begin met een voorbeeld applicatie die het apparaat initialiseert en iets op het scherm tekent. In mijn geval heb ik SDL gedownload, Xcode-iOS/Test/TestiPhoneOS.xcodeproj geopend en vervolgens het testgles2-voorbeeld op mijn iPhone gedraaid.

Voilà! Ik had een mooie draaiende kubus met OpenGL ES 2.0.
Mijn volgende stap was het downloaden van een 3D model dat iemand van Mario had gemaakt. Ik schreef een snelle & vuile OBJ bestand loader – het bestandsformaat is niet zo ingewikkeld – en hackte de voorbeeld applicatie om Mario te renderen in plaats van een kubus. Ik heb ook SDL_Image geintegreerd om te helpen met het laden van textures.

Toen heb ik de dual-stick controls geimplementeerd om Mario te laten bewegen. (In het begin was ik van plan om een dual-stick shooter te maken. Maar niet met Mario.)

Daarna wilde ik de skeletanimatie verkennen, dus opende ik Blender, modelleerde een tentakel en riggde deze met een skelet van twee botten dat heen en weer wiebelde.
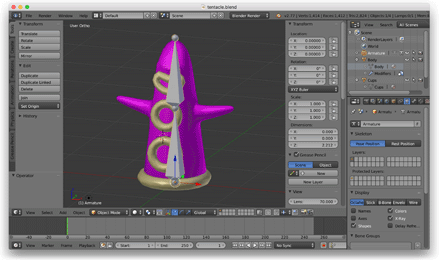
Op dit punt verliet ik het OBJ-bestandsformaat en schreef ik een Python-script om aangepaste JSON-bestanden uit Blender te exporteren. Deze JSON bestanden beschreven de gevilde mesh, skelet en animatie data. Ik laadde deze bestanden in het spel met behulp van een C++ JSON library.

Toen dat eenmaal werkte, ging ik terug naar Blender en maakte ik meer uitgebreide personages. (Dit was de eerste 3D mens die ik ooit gemaakt heb. Ik was best trots op hem.)

De volgende maanden heb ik de volgende stappen genomen:
- Begonnen met het uitwerken van vector- en matrixfuncties in mijn eigen 3D-wiskundebibliotheek.
- Vervangde de
.xcodeprojmet een CMake project. - Kreeg de engine draaiend op zowel Windows als iOS, omdat ik graag in Visual Studio werk.
- Begon met het verplaatsen van code in aparte “engine” en “game” bibliotheken. Na verloop van tijd heb ik die gesplitst in nog meer granulaire bibliotheken.
- Schreef een aparte applicatie om mijn JSON-bestanden om te zetten in binaire gegevens die het spel direct kan laden.
- Heeft uiteindelijk alle SDL-bibliotheken verwijderd uit de iOS-build. (De Windows build gebruikt nog steeds SDL.)
Het punt is: Ik heb de architectuur van de motor niet gepland voordat ik begon te programmeren. Dit was een bewuste keuze. In plaats daarvan schreef ik de eenvoudigste code die de volgende functie implementeerde, daarna keek ik naar de code om te zien wat voor soort architectuur er natuurlijk naar voren kwam. Met “engine-architectuur” bedoel ik de set modules die samen de game-engine vormen, de afhankelijkheden tussen die modules en de API voor interactie met elke module.
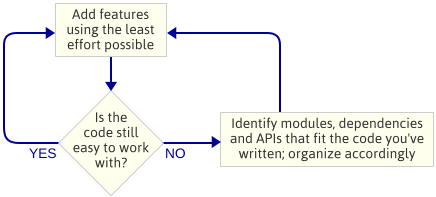
Dit is een iteratieve aanpak omdat het zich richt op kleinere deliverables. Het werkt goed bij het schrijven van een game engine, omdat je bij elke stap een draaiend programma hebt. Als er iets fout gaat bij het verwerken van code in een nieuwe module, kan je altijd je veranderingen vergelijken met de code die eerder werkte. Uiteraard neem ik aan dat je een vorm van source control gebruikt.
Je zou kunnen denken dat er veel tijd verloren gaat met deze aanpak, omdat je altijd slechte code schrijft die later opgeschoond moet worden. Maar het meeste opruimen bestaat uit het verplaatsen van code van het ene .cpp-bestand naar het andere, het uitpakken van functieverklaringen in .h-bestanden, of andere eenvoudige veranderingen. Beslissen waar dingen heen moeten is het moeilijke deel, en dat is makkelijker te doen als de code al bestaat.
Ik zou willen stellen dat er meer tijd wordt verspild met de tegenovergestelde aanpak: Te hard proberen een architectuur te bedenken die alles doet wat je van tevoren denkt nodig te hebben. Twee van mijn favoriete artikelen over de gevaren van over-engineering zijn The Vicious Circle of Generalization door Tomasz Dąbrowski en Don’t Let Architecture Astronauts Scare You door Joel Spolsky.
Ik zeg niet dat je nooit een probleem op papier moet oplossen voordat je het in code aanpakt. Ik zeg ook niet dat je niet van tevoren moet beslissen welke functies je wilt hebben. Ik wist bijvoorbeeld vanaf het begin dat ik wilde dat mijn engine alle assets in een achtergrond thread zou laden. Ik heb alleen niet geprobeerd om die functie te ontwerpen of te implementeren totdat mijn engine daadwerkelijk eerst wat assets had geladen.
De iteratieve aanpak heeft me een veel elegantere architectuur gegeven dan ik ooit had kunnen bedenken door naar een leeg vel papier te staren. De iOS build van mijn engine is nu 100% originele code, inclusief een aangepaste wiskunde bibliotheek, container templates, reflectie/serialisatie systeem, rendering framework, physics en audio mixer. Ik had redenen om elk van die modules te schrijven, maar misschien vind je het niet nodig om al die dingen zelf te schrijven. Er zijn veel geweldige open source bibliotheken met vergunning, die u misschien geschikt vindt voor uw engine. GLM, Bullet Physics en de STB headers zijn slechts een paar interessante voorbeelden.
Think Twice Before Unifying Things Too Much
Als programmeurs proberen we duplicatie van code te vermijden, en we vinden het prettig als onze code een uniforme stijl volgt. Ik denk echter dat het goed is om die instincten niet elke beslissing te laten overheersen.
Resist the DRY Principle Once in a While
Om een voorbeeld te geven, mijn engine bevat verschillende “smart pointer” template classes, vergelijkbaar in geest met std::shared_ptr. Elk helpt geheugenlekken te voorkomen door te dienen als een omhulsel rond een ruwe pointer.
-
Owned<>is voor dynamisch toegewezen objecten die een enkele eigenaar hebben. -
Reference<>gebruikt referentietelling om een object meerdere eigenaren te laten hebben. -
audio::AppOwned<>wordt gebruikt door code buiten de audiomixer. Het staat spelsystemen toe om objecten te bezitten die de audiomixer gebruikt, zoals een stem die op dat moment speelt. -
audio::AudioHandle<>gebruikt een verwijzings-telsysteem intern aan de audiomixer.
Het kan lijken alsof sommige van deze klassen de functionaliteit van de anderen dupliceren, in strijd met het DRY (Don’t Repeat Yourself) Principe. Inderdaad, eerder in de ontwikkeling, probeerde ik de bestaande Reference<> klasse zo veel mogelijk te hergebruiken. Ik ontdekte echter dat de levensduur van een audio object wordt bepaald door speciale regels: Als een audio stem klaar is met het spelen van een sample, en het spel houdt geen pointer naar die stem, dan kan de stem in een wachtrij worden geplaatst om onmiddellijk te worden verwijderd. Als het spel een pointer heeft, dan mag het voice object niet verwijderd worden. En als het spel wel een pointer heeft, maar de eigenaar van de pointer wordt vernietigd voordat de stem is afgelopen, dan moet de stem worden geannuleerd. In plaats van complexiteit toe te voegen aan Reference<>, besloot ik dat het praktischer was om in plaats daarvan aparte template classes te introduceren.
95% van de tijd is het hergebruiken van bestaande code de manier om te gaan. Maar als je je verlamd begint te voelen, of merkt dat je complexiteit toevoegt aan iets dat ooit eenvoudig was, vraag jezelf dan af of iets in de codebase eigenlijk twee dingen zouden moeten zijn.
Het is OK om verschillende aanroepconventies te gebruiken
Een ding dat ik niet leuk vind aan Java is dat het je dwingt om elke functie binnen een klasse te definiëren. Dat is onzin, naar mijn mening. Het laat je code er misschien consistenter uitzien, maar het moedigt ook over-engineering aan en leent zich niet goed voor de iteratieve aanpak die ik eerder beschreef.
In mijn C++ engine, horen sommige functies bij klassen en sommige niet. Bijvoorbeeld, elke vijand in het spel is een klasse, en het meeste gedrag van de vijand is geïmplementeerd in die klasse, zoals je waarschijnlijk zou verwachten. Aan de andere kant worden sphere casts in mijn engine uitgevoerd door sphereCast() aan te roepen, een functie in de physics namespace. sphereCast() behoort tot geen enkele klasse – het is gewoon onderdeel van de physics module. Ik heb een build systeem dat de afhankelijkheden tussen modules beheert, wat de code voor mij goed genoeg georganiseerd houdt. Door deze functie in een willekeurige klasse te wikkelen, wordt de code niet beter georganiseerd.
Dan is er dynamische dispatch, wat een vorm van polymorfisme is. We moeten vaak een functie voor een object aanroepen zonder het exacte type van dat object te kennen. De eerste ingeving van een C++ programmeur is om een abstracte basis klasse te definiëren met virtuele functies, en dan die functies te overschrijven in een afgeleide klasse. Dat is juist, maar het is slechts een techniek. Er zijn andere dynamische dispatch technieken die niet zoveel extra code introduceren, of die andere voordelen bieden:
- C++11 introduceerde
std::function, dat is een handige manier om callback functies op te slaan. Het is ook mogelijk om uw eigen versie vanstd::functionte schrijven die minder pijnlijk is om in de debugger te stappen. - Vele callback functies kunnen worden geïmplementeerd met een paar pointers: Een functie pointer en een ondoorzichtig argument. Het vereist alleen een expliciete cast binnen de callback functie. Je ziet dit veel in pure C bibliotheken.
- Soms is het onderliggende type al bekend tijdens het compileren, en kun je de functie aanroepen zonder extra runtime overhead. Turf, een bibliotheek die ik gebruik in mijn game engine, maakt veel gebruik van deze techniek. Zie
turf::Mutexbijvoorbeeld. Het is gewoon eentypedefover een platform-specifieke klasse. - Soms is de meest eenvoudige aanpak het zelf bouwen en onderhouden van een tabel met raw function pointers. Ik gebruikte deze aanpak in mijn audio mixer en serialisatie systeem. De Python interpreter maakt ook veel gebruik van deze techniek, zoals hieronder vermeld.
- Je kunt zelfs functie-aanwijzers opslaan in een hash-tabel, met de functienamen als sleutels. Ik gebruik deze techniek om invoer-events te dispatchen, zoals multitouch events. Het is onderdeel van een strategie om spelinvoer op te nemen en af te spelen met een replay systeem.
Dynamic dispatch is een groot onderwerp. Ik probeer alleen maar te laten zien dat er veel manieren zijn om het te bereiken. Hoe meer je uitbreidbare low-level code schrijft – wat gebruikelijk is in een game engine – hoe meer je alternatieven zult gaan onderzoeken. Als je niet gewend bent aan dit soort programmeren, is de Python interpreter, die geschreven is in C, een uitstekende bron om van te leren. Het implementeert een krachtig object model: Elke PyObject wijst naar een PyTypeObject, en elke PyTypeObject bevat een tabel met functie-aanwijzers voor dynamische dispatch. Het document Defining New Types is een goed startpunt als je er meteen in wilt springen.
Ben je ervan bewust dat Serialization een groot onderwerp is
Serialization is het omzetten van runtime objecten naar en van een reeks bytes. Met andere woorden, het opslaan en laden van gegevens.
Voor veel, zo niet de meeste game-engines, wordt spelinhoud gemaakt in verschillende bewerkbare formaten zoals .png, .json, .blend of bedrijfseigen formaten, dan uiteindelijk geconverteerd naar platform-specifieke spelformaten die de engine snel kan laden. De laatste toepassing in deze pijplijn wordt vaak een “cooker” genoemd. De cooker kan geïntegreerd zijn in een ander gereedschap, of zelfs verdeeld zijn over meerdere machines. Meestal worden de cooker en een aantal tools ontwikkeld en onderhouden in tandem met de game engine zelf.
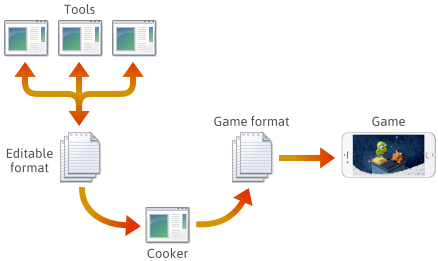
Bij het opzetten van een dergelijke pijplijn is de keuze van het bestandsformaat in elke fase aan u. Misschien definieert u zelf een aantal bestandsindelingen, en deze indelingen kunnen evolueren naarmate u motorfuncties toevoegt. Naarmate ze evolueren, kan het nodig zijn om bepaalde programma’s compatibel te houden met eerder opgeslagen bestanden. Welk formaat u ook gebruikt, uiteindelijk moet u het serieel maken in C++.
Er zijn talloze manieren om serieel maken in C++ te implementeren. Een vrij voor de hand liggende manier is om load en save functies toe te voegen aan de C++ classes die u wilt serialiseren. U kunt achterwaartse compatibiliteit bereiken door een versienummer op te slaan in de header van het bestand, en dit nummer vervolgens door te geven aan elke load functie. Dit werkt, hoewel de code omslachtig kan worden om te onderhouden.
void load(InStream& in, u32 fileVersion) { // Load expected member variables in >> m_position; in >> m_direction; // Load a newer variable only if the file version being loaded is 2 or greater if (fileVersion >= 2) { in >> m_velocity; } }
Het is mogelijk om meer flexibele, minder foutgevoelige serialisatie code te schrijven door gebruik te maken van reflectie – specifiek, door runtime data te maken die de layout van uw C++ types beschrijft. Voor een snel idee van hoe reflectie kan helpen bij serialisatie, kijk eens naar hoe Blender, een open source project, het doet.
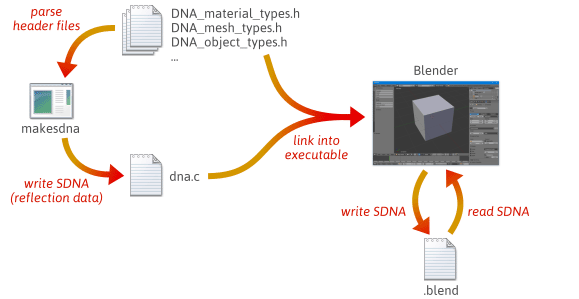
Wanneer je Blender bouwt vanaf broncode, gebeuren er veel stappen. Eerst wordt een aangepast hulpprogramma met de naam makesdna gecompileerd en uitgevoerd. Dit hulpprogramma ontleedt een set C header bestanden in de Blender source tree, en geeft dan een compacte samenvatting van alle C types die daarin gedefinieerd zijn, in een aangepast formaat dat bekend staat als SDNA. Deze SDNA-gegevens dienen als reflectiegegevens. De SDNA wordt vervolgens in Blender zelf gelinkt, en opgeslagen met elk .blend bestand dat Blender schrijft. Vanaf dat moment, wanneer Blender een .blend bestand laadt, vergelijkt het de SDNA van het .blend bestand met de SDNA die is gekoppeld aan de huidige versie tijdens runtime, en gebruikt generieke serialisatie code om eventuele verschillen te verwerken. Deze strategie geeft Blender een indrukwekkende mate van achterwaartse en voorwaartse compatibiliteit. Je kunt nog steeds 1.0 bestanden laden in de nieuwste versie van Blender, en nieuwe .blend bestanden kunnen worden geladen in oudere versies.
Net als Blender, genereren en gebruiken veel game engines – en hun bijbehorende tools – hun eigen reflectie data. Er zijn vele manieren om dit te doen: Je kunt je eigen C/C++ broncode parseren om type-informatie te extraheren, zoals Blender doet. Je kunt een aparte data-beschrijvingstaal maken, en een tool schrijven om C++ type definities en reflectie data uit deze taal te genereren. Je kunt preprocessor macro’s en C++ templates gebruiken om reflectie data te genereren tijdens runtime. En als je eenmaal reflectie data beschikbaar hebt, zijn er talloze manieren om er een generieke serializer bovenop te schrijven.
Het is duidelijk dat ik een hoop details weglaat. In deze post wil ik alleen laten zien dat er veel verschillende manieren zijn om gegevens te serialiseren, waarvan sommige zeer complex zijn. Programmeurs bespreken serialisatie gewoon niet zo veel als andere motorsystemen, ook al vertrouwen de meeste andere systemen erop. Bijvoorbeeld, van de 96 programmeerpraatjes die op GDC 2017 werden gegeven, telde ik 31 praatjes over graphics, 11 over online, 10 over tools, 4 over AI, 3 over physics, 2 over audio – maar slechts één die direct over serialisatie ging.
Probeer op zijn minst een idee te hebben hoe complex je behoeften zullen zijn. Als je een klein spel als Flappy Bird maakt, met slechts een paar assets, hoef je waarschijnlijk niet al te veel na te denken over serialisatie. Je kan waarschijnlijk texturen rechtstreeks vanuit PNG laden en het zal in orde zijn. Als je een compact binair formaat nodig hebt met achterwaartse compatibiliteit, maar niet je eigen wilt ontwikkelen, kijk dan eens naar bibliotheken van derden, zoals Cereal of Boost.Serialization. Ik denk niet dat Google Protocol Buffers ideaal zijn voor het serialiseren van spel-assets, maar ze zijn desalniettemin het bestuderen waard.
Het schrijven van een game engine – zelfs een kleine – is een grote onderneming. Er is veel meer dat ik erover zou kunnen zeggen, maar voor een post van deze lengte, is dat eerlijk gezegd het meest nuttige advies dat ik kan bedenken om te geven: Werk iteratief, weersta de drang om code een beetje te uniformeren, en weet dat serialisatie een groot onderwerp is zodat je een passende strategie kunt kiezen. Mijn ervaring is dat elk van deze dingen een struikelblok kan worden als je het negeert.
Ik hou ervan om aantekeningen te vergelijken over dit soort dingen, dus ik zou het erg interessant vinden om van andere ontwikkelaars te horen. Als je een motor hebt geschreven, heeft je ervaring je tot dezelfde conclusies geleid? En als je er nog geen geschreven hebt, of er gewoon over nadenkt, ben ik ook geïnteresseerd in jouw gedachten. Wat is volgens jou een goede bron om van te leren? Welke delen zijn voor jou nog mysterieus? Voel je vrij om hieronder een reactie achter te laten of contact met me op te nemen op Twitter!