最近、C++でゲームエンジンを書いているんです。 それを使って、Hop Outという小さな携帯ゲームを作っています。 iPhone 6からキャプチャした映像です。 (サウンドのためにミュートを解除してください!)

Hop Out は、私がプレイしたいタイプのゲームです。 レトロなアーケードゲームに3Dアニメのようなルックス。
Hop Outはまだ開発中ですが、搭載しているエンジンがかなり成熟してきたので、ここでエンジン開発に関するいくつかのヒントを共有しようと思います。
- あなたが「いじっぱり」だからです。
- ゲーム開発についてもっと学びたい。 私はゲーム業界で14年間を過ごしましたが、まだ理解できないでいます。 大きなスタジオでのプログラミングの仕事の日々の責任とは大きく異なるので、ゼロからエンジンを書けるかどうかもわかりませんでした。
- コントロールがお好きなんですね。 AGI (1984) や id Tech 1 (1993) 、Build (1995) などのクラシックなゲーム エンジンや、Unity や Unreal といった業界の巨人からインスピレーションを受けています。 私たちはゲーム作りの技術を習得したわけではありません。 それどころではありません。
2017年のゲームプラットフォーム(モバイル、コンソール、PC)は非常に強力で、多くの点で、互いに非常によく似ています。 ゲームエンジン開発は、かつてのように、弱小でエキゾチックなハードウェアと格闘するようなものではありません。 むしろ、自分で作った複雑なものと格闘することが重要だと私は考えています。 モンスターを作るのは簡単です ですから、この記事では、管理しやすい状態を保つことを中心にアドバイスしています。 5431>
- Use an iterative approach
- Think twice before unifying things too much
- Be aware that serialization is a big subject
The advice applies to any kind of game engine.USE は、ゲーム エンジンの種類に関係なく適用できます。 シェーダーの書き方や、オクトリーとは何か、物理の追加方法などを教えるつもりはありません。 それらは、あなたがすでに知っているはずのことであり、あなたが作りたいゲームの種類に大きく依存します。 その代わり、広く認識されていない、あるいは話題になっていないような点を意図的に選びました。
Use an Iterative Approach
私の最初のアドバイスは、何か (何か!) をすばやく実行し、それから反復することです。 私の場合、SDL をダウンロードし、Xcode-iOS/Test/TestiPhoneOS.xcodeproj を開いて、testgles2 サンプルを iPhone で実行しました。

Voilà! OpenGL ES 2.0 を使用して、美しい回転するキューブを作成しました。
次のステップは、誰かが作ったマリオの 3D モデルをダウンロードすることでした。 ファイル形式はそれほど複雑ではないので、手早く & ダーティな OBJ ファイル ローダーを書き、サンプル アプリケーションをハックして、立方体の代わりにマリオをレンダリングしました。 また、テクスチャを読み込むために SDL_Image を統合しました。

それから、マリオを動かすためにデュアルスティックによるコントロールを実装しました。 (当初はシューティングゲームを作ろうと思っていました。

次にスケルトンアニメーションを模索し、Blenderを開いて触手をモデリングし、前後に動く2ボーン骨格のリギングを行いました。 これらの JSON ファイルは、スキニングされたメッシュ、スケルトン、およびアニメーション データを記述したものです。 これらのファイルは、C++ JSON ライブラリの助けを借りて、ゲームにロードしました。 (これは、私が初めて作成したリグ付きの 3D 人間です。 5431>

その後数か月間、次のステップを踏みました:
- ベクトルとマトリックス関数を自分自身の 3D 数学ライブラリにファクタリングすることを開始しました。
-
.xcodeprojを CMake プロジェクトと置き換えました。 - Visual Studio で作業するのが好きなので、Windows と iOS の両方でエンジンを動作させるようにしました。
- JSON ファイルをゲームが直接読み込めるバイナリ データに変換するための別のアプリケーションを書きました。 (Windows ビルドはまだ SDL を使用しています。)
要点は。 私はプログラミングを始める前に、エンジン アーキテクチャを計画しませんでした。 これは意図的な選択でした。 その代わり、次の機能を実装する最も単純なコードを書き、そのコードを見て、どのようなアーキテクチャが自然に出てくるかを確認しました。 エンジン アーキテクチャ」とは、ゲーム エンジンを構成する一連のモジュール、それらのモジュール間の依存関係、および各モジュールとやり取りするための API を意味します。 ゲーム エンジンを書くときは、途中の各ステップで実行中のプログラムがあるため、うまくいきます。 新しいモジュールにコードを組み込んでいるときに何か問題が発生した場合、変更したコードと以前動作していたコードをいつでも比較することができます。 当然ながら、何らかのソース管理を使用していると仮定します。
このアプローチでは、常に悪いコードを書いていて、後で整理する必要があるため、多くの時間が無駄になると思うかもしれません。 しかし、クリーンアップのほとんどは、コードをある .cpp ファイルから別のファイルに移動したり、関数宣言を .h ファイルに抽出したり、同じように単純な変更になったりします。 どこに行くべきかを決めるのは難しいことで、コードがすでに存在していれば、それは簡単なことです。 つまり、前もって必要と思われるすべてのことを行うアーキテクチャを考え出すのに一生懸命になることです。 過剰なエンジニアリングの危険性についての私のお気に入りの記事は、Tomasz Dąbrowski による「一般化の悪循環」と Joel Spolsky による「建築家の宇宙飛行士を怖がらせてはいけない」の 2 つです。 また、どのような機能が必要かを事前に決めるべきではないとも言いません。 たとえば、私は最初から、エンジンがバックグラウンド スレッドですべてのアセットをロードすることを望んでいることを知っていました。 しかし、エンジンが実際にアセットを読み込むまでは、その機能を設計したり実装したりしませんでした。
反復的なアプローチにより、白紙を見つめて思いついたものよりはるかにエレガントなアーキテクチャを得ることができました。 私のエンジンの iOS ビルドは、カスタム数学ライブラリ、コンテナ テンプレート、リフレクション/シリアライズ システム、レンダリング フレームワーク、物理、オーディオ ミキサーなど、100% オリジナル コードになっています。 私は、それぞれのモジュールを書く理由がありましたが、皆さんは、これらすべてを自分で書く必要はないと思われるかもしれません。 その代わりに、あなたのエンジンにふさわしいと思われる、素晴らしい、寛容にライセンスされたオープンソースライブラリがたくさんあります。 GLM、Bullet Physics、STB ヘッダーなどはその一例です。
Think Twice Before Unification Things Too Much
プログラマとして、コードの重複を避け、コードが均一なスタイルに従っていることが好ましいと思います。 しかし、そのような直感がすべての決定を覆すことは良くないと思います。
Resist the DRY Principle Once in a While
例を挙げると、私のエンジンにはいくつかの「スマート ポインター」テンプレート クラスがあり、std::shared_ptr と同様の精神を持っています。
-
Owned<>は単一のオーナーを持つ動的に割り当てられたオブジェクトのためのものです。 -
Reference<>は参照カウントを使用して、オブジェクトが複数のオーナーを持つことを可能にします。 -
audio::AppOwned<>はオーディオ ミキサーの外部のコードで使用され、ゲーム システムが、現在再生中の音声など、オーディオ ミキサーが使用するオブジェクトを所有できるようにします。 -
audio::AudioHandle<>はオーディオ ミキサーの内部で参照カウント システムを使用します。 実際、開発の初期には、既存のReference<>クラスをできるだけ再利用するようにしました。 しかし、オーディオオブジェクトの寿命は特別なルールで管理されていることがわかりました。 オーディオボイスがサンプルの再生を終了し、ゲームがそのボイスへのポインタを保持していない場合、そのボイスはすぐに削除のためにキューに入れられるのです。 ゲーム側がポインタを保持している場合、ボイスオブジェクトは削除されるべきではありません。 また、ゲームがポインタを保持していても、音声が終了する前にポインタのオーナーが破壊された場合、音声はキャンセルされるべきです。Reference<>に複雑さを加えるよりも、代わりに別のテンプレート クラスを導入する方がより実用的だと判断しました。95% の場合、既存のコードを再利用することが望ましい方法です。 しかし、麻痺していると感じ始めたり、かつて単純だったものに複雑さを加えていることに気づいたら、コードベース内の何かが実際に2つのものであるべきなのかどうか自問自答してください。 私の意見では、それはナンセンスです。 コードの一貫性を高めるかもしれませんが、過剰なエンジニアリングを助長し、私が以前に説明した反復的なアプローチには適していません。 たとえば、ゲーム内のすべての敵はクラスであり、敵の動作のほとんどは、おそらく皆さんが期待するように、そのクラスの内部で実装されています。 一方、私のエンジンでは、球体のキャストは
physics名前空間の関数であるsphereCast()を呼び出すことで行われます。sphereCast()はどのクラスにも属しておらず、physicsモジュールの一部に過ぎません。 私はモジュール間の依存関係を管理するビルドシステムを持っているので、コードを十分に整理することができます。 この関数を任意のクラスでラップしても、コードの構成が改善されることはありません。次に、ポリモーフィズムの一種である動的ディスパッチがあります。 私たちはしばしば、あるオブジェクトの正確な型を知らずに、そのオブジェクトの関数を呼び出す必要があります。 C++プログラマの最初の直感は、仮想関数を持つ抽象的な基底クラスを定義し、派生クラスでそれらの関数をオーバーライドすることです。 それはそれで正しいのだが、一つの手法に過ぎない。 これほど多くの余分なコードを導入しない、あるいは他の利点をもたらす動的ディスパッチ技法は他にもあります。
- C++11 では、コールバック関数を格納する便利な方法として
std::functionが導入されました。 また、デバッガーで踏み込む苦痛が少ない独自のバージョンのstd::functionを書くことも可能です。 - 多くのコールバック関数は、ポインターのペアで実装することができます。 関数ポインターと不透明な引数です。 これは、コールバック関数内部で明示的なキャストを必要とするだけです。
- 場合によっては、基礎となる型がコンパイル時に実際に知られており、追加の実行時オーバーヘッドなしに関数呼び出しを結合することができます。 私のゲームエンジンで使用しているライブラリである Turf は、このテクニックに多く依存しています。 たとえば、
turf::Mutexを見てください。 これは、プラットフォーム固有のクラス上のtypedefです。 - 時には、最も簡単なアプローチは、生の関数ポインタのテーブルを自分で構築し、維持することです。 私はこのアプローチをオーディオ ミキサーとシリアライゼーション システムで使用しました。 Python インタープリターも、後述するようにこの手法を多用しています。
- キーとして関数名を使用し、ハッシュ テーブルに関数ポインターを格納することもできます。 私はこの技法を、マルチタッチ イベントなどの入力イベントのディスパッチに使用しています。 これは、ゲームの入力を記録し、リプレイ システムで再生する戦略の一部です。
動的ディスパッチは大きなテーマです。 私は、それを実現する多くの方法があることを示すために表面を削っているだけです。 ゲーム エンジンでは一般的ですが、拡張可能な低レベル コードを書けば書くほど、代替手段を模索していることに気づくでしょう。 このようなプログラミングに慣れていない場合、C言語で書かれたPythonインタプリタは、学ぶのに最適なリソースとなります。 Pythonは強力なオブジェクトモデルを実装しています。 すべての
PyObjectはPyTypeObjectを指し、すべてのPyTypeObjectは動的ディスパッチのための関数ポインタのテーブルを含んでいます。 ドキュメント「Defining New Types」は、すぐに飛び込むには良い出発点です。Be Aware that Serialization Is a Big Subject
シリアル化は、実行時のオブジェクトを一連のバイト列に変換する行為である。 ほとんどのゲーム エンジンでは、ゲーム コンテンツは
.png、.json、.blendなどのさまざまな編集可能な形式や独自の形式で作成され、最終的にエンジンが迅速にロードできるプラットフォーム固有のゲーム形式に変換されます。 このパイプラインの最後のアプリケーションは、しばしば「クッカー」と呼ばれます。 クッカーは他のツールに統合されることもありますし、複数のマシンに分散されることもあります。 通常、クッカーといくつかのツールは、ゲーム エンジン本体と並行して開発および保守されます。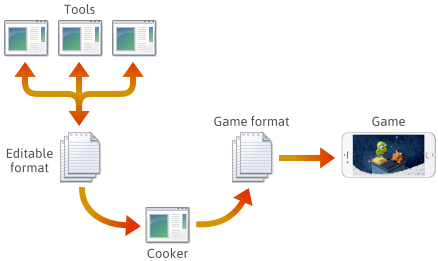
このようなパイプラインを設定する場合、各段階でのファイル形式の選択はあなた次第となります。 独自のファイル形式を定義することもできますし、エンジン機能の追加に伴い、それらの形式も進化していくかもしれません。 進化するにつれて、特定のプログラムを以前に保存したファイルと互換性を保つことが必要になるかもしれません。 どのような形式であっても、最終的には C++ でシリアライズする必要があります。
C++でシリアライズを実装する方法は無数にあります。 かなり明白な方法の 1 つは、シリアライズしたい C++ クラスに
loadとsaveの関数を追加することです。 ファイルヘッダにバージョン番号を格納し、この番号をすべてのload関数に渡すことで、後方互換性を確保することができます。void load(InStream& in, u32 fileVersion) { // Load expected member variables in >> m_position; in >> m_direction; // Load a newer variable only if the file version being loaded is 2 or greater if (fileVersion >= 2) { in >> m_velocity; } }Reflection を活用することにより、より柔軟でエラーが起こりにくいシリアライズ コードを書くことが可能です。 リフレクションがシリアライゼーションにどのように役立つかの簡単なアイデアとして、オープンソースプロジェクトである Blender がそれをどのように行っているかを見てみましょう。
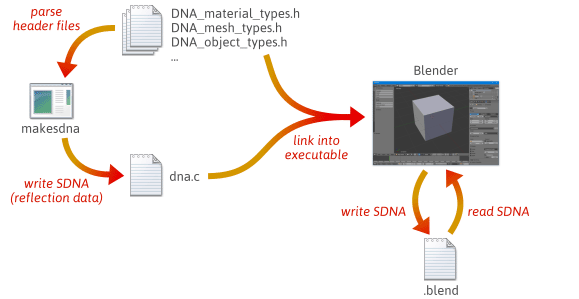
Blenderをソースコードからビルドするとき、多くのステップが発生します。 まず、
makesdnaという名前のカスタムユーティリティがコンパイルされ、実行されます。 このユーティリティは Blender のソース ツリーにある一連の C ヘッダー ファイルを解析し、その中で定義されているすべての C タイプのコンパクトなサマリーを SDNA として知られるカスタム フォーマットで出力します。 この SDNA データはリフレクションデータとして機能します。 SDNAはその後Blender自体にリンクされ、Blenderが書き込むすべての.blendファイルとともに保存されます。 それ以降、Blenderが.blendファイルをロードするときはいつでも、.blendファイルのSDNAと実行時に現在のバージョンにリンクされたSDNAを比較し、あらゆる違いを処理するために汎用シリアライゼーションコードを使用します。 この戦略により、Blenderは印象的な程度の後方および前方互換性を得ることができます。 Blender の最新バージョンで 1.0 ファイルをロードでき、新しい.blendファイルは古いバージョンでロードできます。Blender と同様に、多くのゲームエンジン、および関連ツールは独自の反映データを生成し、使用します。 それを行う方法はたくさんあります。 Blender がそうであるように、独自の C/C++ ソース コードを解析して型情報を抽出することができます。 Blenderがそうであるように、あなた自身のC/C++ソースコードを解析して型情報を抽出できます。あなたは別のデータ記述言語を作成し、この言語からC++型定義とリフレクションデータを生成するツールを書くことができます。 プリプロセッサのマクロやC++のテンプレートを使って、実行時にリフレクションデータを生成することも可能です。 そして、いったんReflectionデータが利用可能になれば、その上で汎用シリアライザを書く方法は無数にあります。
明らかに、私は多くの詳細を省略しています。 この投稿では、データをシリアライズする多くの異なる方法があり、そのいくつかは非常に複雑であることを示したいだけです。 他のほとんどのシステムがシリアライゼーションに依存しているにもかかわらず、プログラマは他のエンジンシステムほどシリアライゼーションについて議論しません。 たとえば、GDC 2017 で行われた 96 のプログラミング講演のうち、グラフィックスに関する講演は 31、オンラインに関する講演は 11、ツールに関する講演は 10、AI に関する講演は 4、物理に関する講演は 3、オーディオに関する講演は 2、しかしシリアライゼーションに直接触れたのは 1 つだけでした。 Flappy Bird のような小さなゲームで、アセットが数個しかない場合は、シリアライゼーションについてあまり難しく考える必要はないでしょう。 PNGから直接テクスチャを読み込んでも、おそらく問題ないでしょう。 後方互換性のあるコンパクトなバイナリ形式が必要だが、自分で開発したくない場合は、Cereal や Boost.Serialization などのサードパーティライブラリを参照してみてください。 Google Protocol Buffers がゲーム アセットのシリアライズに理想的だとは思いませんが、それでも研究する価値はあります。
ゲーム エンジンを書くことは、たとえ小さなものであっても、大きな仕事です。 それについてもっと言いたいことはたくさんありますが、この長さの投稿では、正直なところ、これが最も役立つアドバイスです。 繰り返し作業すること、コードを統一したいという衝動に少し耐えること、シリアライゼーションが大きなテーマであることを知って適切な戦略を選択できるようにすることです。 私の経験では、これらのことは無視するとつまずきの原因になります。
私はこのようなことについてノートを比較するのが好きなので、他の開発者の意見を聞きたいと思います。 もしあなたがエンジンを書いたことがあるなら、その経験から同じような結論に至ったことはありますか。 また、まだ書いていない人、あるいはちょうど考えている人、あなたの考えにも興味があります。 どのような資料から学ぶのが良いと思われますか? どのような部分がまだ神秘的に見えますか? お気軽に下のコメント欄やTwitterでご連絡ください!
。
- C++11 では、コールバック関数を格納する便利な方法として