Oggi ho scritto un motore di gioco in C++. Lo sto usando per fare un piccolo gioco per cellulari chiamato Hop Out. Ecco una clip catturata dal mio iPhone 6. (Disattiva il suono!)

Hop Out è il tipo di gioco che voglio fare: Un gioco arcade retrò con un look da cartone animato in 3D. L’obiettivo è cambiare il colore di ogni pad, come in Q*Bert.
Hop Out è ancora in fase di sviluppo, ma il motore che lo alimenta sta iniziando a diventare abbastanza maturo, quindi ho pensato di condividere qui alcuni consigli sullo sviluppo del motore.
Perché vorresti scrivere un motore di gioco? Ci sono molte possibili ragioni:
- Sei un armeggiatore. Ami costruire sistemi da zero e vederli prendere vita.
- Vuoi imparare di più sullo sviluppo dei giochi. Ho passato 14 anni nell’industria dei giochi e sto ancora cercando di capire. Non ero nemmeno sicuro di poter scrivere un motore da zero, poiché è molto diverso dalle responsabilità quotidiane di un lavoro di programmazione in un grande studio. Volevo scoprirlo.
- Ti piace il controllo. È soddisfacente organizzare il codice esattamente come vuoi, sapendo dove tutto è in ogni momento.
- Ti senti ispirato dai classici motori di gioco come AGI (1984), id Tech 1 (1993), Build (1995), e dai giganti dell’industria come Unity e Unreal.
- Credete che noi, l’industria dei giochi, dovremmo provare a demistificare il processo di sviluppo del motore. Non è che abbiamo padroneggiato l’arte di fare giochi. Tutt’altro! Più esaminiamo questo processo, maggiori sono le nostre possibilità di migliorarlo.
Le piattaforme di gioco del 2017 – mobile, console e PC – sono molto potenti e, per molti versi, abbastanza simili tra loro. Lo sviluppo di motori di gioco non è tanto alle prese con un hardware debole ed esotico, come lo era in passato. A mio parere, si tratta piuttosto di lottare con la complessità che ci si crea da soli. È facile creare un mostro! Ecco perché i consigli in questo post sono incentrati sul mantenere le cose gestibili. L’ho organizzato in tre sezioni:
- Usa un approccio iterativo
- Pensaci due volte prima di unificare troppo le cose
- Sii consapevole che la serializzazione è un grande argomento
Questo consiglio vale per qualsiasi tipo di motore di gioco. Non vi dirò come scrivere uno shader, cos’è un octree o come aggiungere la fisica. Questi sono i tipi di cose che, presumo, sapete già che dovreste sapere – e dipende in gran parte dal tipo di gioco che volete fare. Invece, ho deliberatamente scelto dei punti che non sembrano essere ampiamente riconosciuti o discussi – questi sono i tipi di punti che trovo più interessanti quando cerco di demistificare un argomento.
Usa un approccio iterativo
Il mio primo consiglio è di far girare qualcosa (qualsiasi cosa!) velocemente, poi iterare.
Se possibile, iniziate con un’applicazione di esempio che inizializzi il dispositivo e disegni qualcosa sullo schermo. Nel mio caso, ho scaricato SDL, ho aperto Xcode-iOS/Test/TestiPhoneOS.xcodeproj, poi ho eseguito il campione testgles2 sul mio iPhone.

Voilà! Avevo un bel cubo che girava usando OpenGL ES 2.0.
Il mio prossimo passo era scaricare un modello 3D di Mario fatto da qualcuno. Ho scritto un veloce &caricatore di file OBJ sporco – il formato del file non è così complicato – e ho modificato l’applicazione di esempio per renderizzare Mario invece di un cubo. Ho anche integrato SDL_Image per aiutare a caricare le texture.

Poi ho implementato i controlli dual-stick per muovere Mario. (All’inizio, stavo pensando di fare uno sparatutto dual-stick. Non con Mario, però.)

Poi, volevo esplorare l’animazione scheletrica, così ho aperto Blender, modellato un tentacolo, e l’ho truccato con uno scheletro a due ossa che si muoveva avanti e indietro.
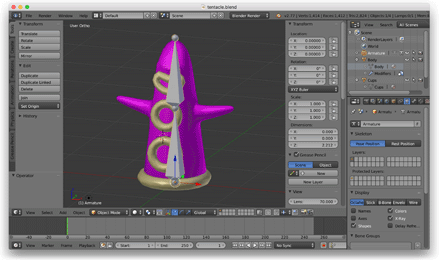
A questo punto, ho abbandonato il formato OBJ e scritto uno script Python per esportare file JSON personalizzati da Blender. Questi file JSON descrivevano la mesh scuoiata, lo scheletro e i dati di animazione. Ho caricato questi file nel gioco con l’aiuto di una libreria C++ JSON.

Una volta che ha funzionato, sono tornato in Blender e ho creato un personaggio più elaborato. (Questo è stato il primo umano 3D rigged che abbia mai creato. Ero abbastanza orgoglioso di lui.)

Nei mesi successivi, ho fatto i seguenti passi:
- Ho iniziato a fattorizzare le funzioni vettoriali e matriciali nella mia libreria matematica 3D.
- Ho sostituito il
.xcodeprojcon un progetto CMake. - Ho fatto funzionare il motore sia su Windows che su iOS, perché mi piace lavorare in Visual Studio.
- Ho iniziato a spostare il codice in librerie separate “motore” e “gioco”. Col tempo, le ho divise in librerie ancora più granulari.
- Ho scritto un’applicazione separata per convertire i miei file JSON in dati binari che il gioco può caricare direttamente.
- Ho finalmente rimosso tutte le librerie SDL dalla build per iOS. (La build per Windows usa ancora SDL.)
Il punto è: Non ho pianificato l’architettura del motore prima di iniziare a programmare. Questa è stata una scelta deliberata. Invece, ho solo scritto il codice più semplice che implementava la caratteristica successiva, poi guardavo il codice per vedere che tipo di architettura emergeva naturalmente. Con “architettura del motore”, intendo l’insieme dei moduli che compongono il motore di gioco, le dipendenze tra questi moduli e le API per interagire con ogni modulo.
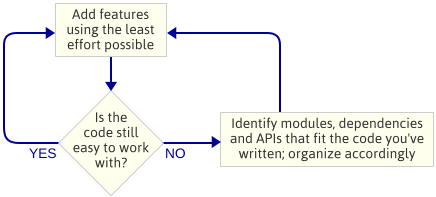
Questo è un approccio iterativo perché si concentra su piccoli risultati. Funziona bene quando si scrive un motore di gioco perché, ad ogni passo lungo la strada, si ha un programma in esecuzione. Se qualcosa va storto quando state inserendo il codice in un nuovo modulo, potete sempre confrontare le vostre modifiche con il codice che ha funzionato in precedenza. Ovviamente, presumo che stiate usando un qualche tipo di controllo dei sorgenti.
Potreste pensare che con questo approccio si perde un sacco di tempo, dato che state sempre scrivendo del cattivo codice che deve essere ripulito in seguito. Ma la maggior parte della pulizia riguarda lo spostamento di codice da un file .cpp ad un altro, l’estrazione di dichiarazioni di funzioni in file .h, o cambiamenti altrettanto semplici. Decidere dove le cose dovrebbero andare è la parte difficile, e questo è più facile da fare quando il codice esiste già.
Direi che si perde più tempo nell’approccio opposto: Cercare troppo duramente di arrivare con un’architettura che farà tutto ciò di cui pensate di aver bisogno in anticipo. Due dei miei articoli preferiti sui pericoli dell’over-engineering sono The Vicious Circle of Generalization di Tomasz Dąbrowski e Don’t Let Architecture Astronauts Scare You di Joel Spolsky.
Non sto dicendo che non si dovrebbe mai risolvere un problema sulla carta prima di affrontarlo nel codice. Non sto nemmeno dicendo che non dovreste decidere quali caratteristiche volete in anticipo. Per esempio, sapevo fin dall’inizio che volevo che il mio motore caricasse tutte le risorse in un thread in background. Solo che non ho cercato di progettare o implementare questa caratteristica fino a quando il mio motore non ha effettivamente caricato alcune risorse per primo.
L’approccio iterativo mi ha dato un’architettura molto più elegante di quanto avrei mai potuto sognare fissando un foglio di carta bianco. La build iOS del mio motore è ora 100% codice originale, compresa una libreria matematica personalizzata, modelli di contenitori, sistema di riflessione/serializzazione, quadro di rendering, fisica e mixer audio. Avevo delle ragioni per scrivere ognuno di questi moduli, ma potreste non trovare necessario scrivere tutte queste cose da soli. Ci sono un sacco di grandi librerie open source con licenza permissiva che potreste invece trovare appropriate per il vostro motore. GLM, Bullet Physics e gli header STB sono solo alcuni esempi interessanti.
Pensaci bene prima di unificare troppo le cose
Come programmatori, cerchiamo di evitare la duplicazione del codice, e ci piace quando il nostro codice segue uno stile uniforme. Tuttavia, penso che sia bene non lasciare che questi istinti prevalgano su ogni decisione.
Resistere al principio DRY una volta ogni tanto
Per darvi un esempio, il mio motore contiene diverse classi template “smart pointer”, simili nello spirito a std::shared_ptr. Ognuna di esse aiuta a prevenire le perdite di memoria servendo da involucro intorno a un puntatore grezzo.
-
Owned<>è per gli oggetti allocati dinamicamente che hanno un singolo proprietario. -
Reference<>usa il conteggio dei riferimenti per permettere a un oggetto di avere diversi proprietari. -
audio::AppOwned<>è usato dal codice fuori dal mixer audio. Permette ai sistemi di gioco di possedere oggetti che il mixer audio usa, come una voce che sta giocando. -
audio::AudioHandle<>usa un sistema di conteggio dei riferimenti interno al mixer audio.
Può sembrare che alcune di queste classi duplichino le funzionalità delle altre, in violazione del principio DRY (Don’t Repeat Yourself). Infatti, all’inizio dello sviluppo, ho cercato di riutilizzare il più possibile la classe Reference<> esistente. Tuttavia, ho scoperto che la vita di un oggetto audio è governata da regole speciali: Se una voce audio ha finito di suonare un campione, e il gioco non possiede un puntatore a quella voce, la voce può essere messa in coda per essere cancellata immediatamente. Se il gioco possiede un puntatore, allora l’oggetto voce non dovrebbe essere cancellato. E se il gioco possiede un puntatore, ma il proprietario del puntatore viene distrutto prima che la voce sia finita, la voce dovrebbe essere cancellata. Piuttosto che aggiungere complessità a Reference<>, ho deciso che era più pratico introdurre invece delle classi template separate.
95% del tempo, riutilizzare il codice esistente è la strada da percorrere. Ma se cominciate a sentirvi paralizzati, o vi trovate ad aggiungere complessità a qualcosa che una volta era semplice, chiedetevi se qualcosa nel codice dovrebbe essere effettivamente due cose.
E’ giusto usare convenzioni di chiamata diverse
Una cosa che non mi piace di Java è che vi costringe a definire ogni funzione all’interno di una classe. Questo non ha senso, secondo me. Potrebbe far sembrare il vostro codice più coerente, ma incoraggia anche un eccesso di ingegneria e non si presta bene all’approccio iterativo che ho descritto prima.
Nel mio motore C++, alcune funzioni appartengono a classi e altre no. Per esempio, ogni nemico nel gioco è una classe, e la maggior parte del comportamento del nemico è implementato all’interno di quella classe, come probabilmente vi aspettereste. D’altra parte, i cast delle sfere nel mio motore sono eseguiti chiamando sphereCast(), una funzione nel namespace physics. sphereCast() non appartiene a nessuna classe – è solo parte del modulo physics. Ho un sistema di compilazione che gestisce le dipendenze tra i moduli, che mantiene il codice organizzato abbastanza bene per me. Avvolgere questa funzione dentro una classe arbitraria non migliorerà l’organizzazione del codice in nessun modo significativo.
Poi c’è il dispatch dinamico, che è una forma di polimorfismo. Abbiamo spesso bisogno di chiamare una funzione per un oggetto senza conoscere il tipo esatto di quell’oggetto. Il primo istinto di un programmatore C++ è quello di definire una classe base astratta con funzioni virtuali, poi sovrascrivere quelle funzioni in una classe derivata. Questo è valido, ma è solo una tecnica. Ci sono altre tecniche di dispacciamento dinamico che non introducono tanto codice extra, o che portano altri benefici:
- C++11 ha introdotto
std::function, che è un modo conveniente per memorizzare funzioni di callback. È anche possibile scrivere la propria versione distd::functionche è meno dolorosa da mettere in atto nel debugger. - Molte funzioni di callback possono essere implementate con una coppia di puntatori: Un puntatore di funzione e un argomento opaco. Richiede solo un cast esplicito all’interno della funzione di callback. Lo si vede spesso nelle librerie C pure.
- A volte, il tipo sottostante è effettivamente noto in fase di compilazione, e si può legare la chiamata alla funzione senza alcun overhead aggiuntivo di runtime. Turf, una libreria che uso nel mio motore di gioco, si basa molto su questa tecnica. Vedi
turf::Mutexper esempio. È solo untypedefsu una classe specifica della piattaforma. - A volte, l’approccio più diretto è quello di costruire e mantenere una tabella di puntatori a funzioni grezze. Ho usato questo approccio nel mio mixer audio e nel mio sistema di serializzazione. Anche l’interprete Python fa un uso pesante di questa tecnica, come menzionato di seguito.
- Si possono anche memorizzare i puntatori di funzione in una tabella hash, usando i nomi delle funzioni come chiavi. Io uso questa tecnica per distribuire eventi di input, come gli eventi multitouch. Fa parte di una strategia per registrare gli input di gioco e riprodurli con un sistema di replay.
Il dispatch dinamico è un grande argomento. Sto solo grattando la superficie per mostrare che ci sono molti modi per realizzarlo. Più scrivete codice estendibile a basso livello – che è comune in un motore di gioco – più vi troverete ad esplorare alternative. Se non siete abituati a questo tipo di programmazione, l’interprete Python, che è scritto in C, è una risorsa eccellente per imparare. Implementa un potente modello ad oggetti: Ogni PyObject punta ad un PyTypeObject, e ogni PyTypeObject contiene una tabella di puntatori a funzioni per il dispatch dinamico. Il documento Defining New Types è un buon punto di partenza se si vuole saltare direttamente dentro.
Be Aware that Serialization Is a Big Subject
Serializzazione è l’atto di convertire oggetti runtime da e verso una sequenza di byte. In altre parole, salvare e caricare dati.
Per molti se non la maggior parte dei motori di gioco, il contenuto del gioco viene creato in vari formati modificabili come .png, .json, .blend o formati proprietari, poi alla fine viene convertito in formati di gioco specifici della piattaforma che il motore può caricare rapidamente. L’ultima applicazione in questa pipeline è spesso chiamata “cucinatore”. Il cuocitore potrebbe essere integrato in un altro strumento, o anche distribuito su diverse macchine. Di solito, il cuocitore e un certo numero di strumenti sono sviluppati e mantenuti in tandem con il motore di gioco stesso.
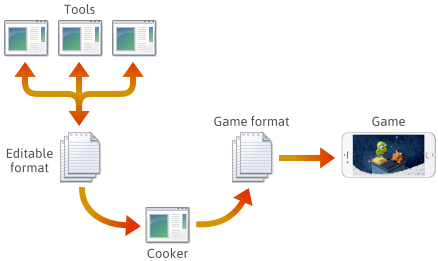
Quando si imposta una tale pipeline, la scelta del formato dei file in ogni fase dipende da voi. Potreste definire alcuni formati di file per conto vostro, e questi formati potrebbero evolvere man mano che aggiungete funzionalità al motore. Mentre si evolvono, potreste trovare necessario mantenere alcuni programmi compatibili con i file precedentemente salvati. Non importa quale sia il formato, alla fine avrete bisogno di serializzarlo in C++.
Ci sono innumerevoli modi per implementare la serializzazione in C++. Un modo abbastanza ovvio è quello di aggiungere load e save funzioni alle classi C++ che volete serializzare. Potete ottenere la compatibilità all’indietro memorizzando un numero di versione nell’intestazione del file, quindi passando questo numero in ogni funzione load. Questo funziona, anche se il codice può diventare ingombrante da mantenere.
void load(InStream& in, u32 fileVersion) { // Load expected member variables in >> m_position; in >> m_direction; // Load a newer variable only if the file version being loaded is 2 or greater if (fileVersion >= 2) { in >> m_velocity; } }
È possibile scrivere un codice di serializzazione più flessibile e meno soggetto a errori sfruttando la reflection – in particolare, creando dati runtime che descrivono il layout dei vostri tipi C++. Per una rapida idea di come la riflessione può aiutare la serializzazione, date un’occhiata a come Blender, un progetto open source, lo fa.
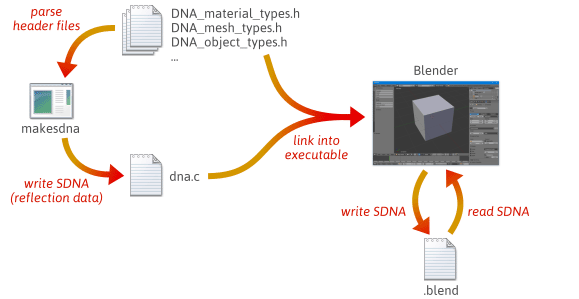
Quando costruisci Blender dal codice sorgente, avvengono molti passi. Per prima cosa, una utility personalizzata chiamata makesdna viene compilata ed eseguita. Questa utility analizza un insieme di file header C nell’albero dei sorgenti di Blender, quindi produce un riassunto compatto di tutti i tipi C definiti al suo interno, in un formato personalizzato noto come SDNA. Questi dati SDNA servono come dati di riflessione. L’SDNA è poi collegato a Blender stesso, e salvato con ogni file .blend che Blender scrive. Da quel momento in poi, ogni volta che Blender carica un file .blend, confronta l’SDNA del file .blend con l’SDNA collegato alla versione corrente in fase di esecuzione, e usa un codice di serializzazione generico per gestire qualsiasi differenza. Questa strategia dà a Blender un impressionante grado di compatibilità all’indietro e in avanti. Puoi ancora caricare i file 1.0 nell’ultima versione di Blender, e i nuovi .blend file possono essere caricati nelle vecchie versioni.
Come Blender, molti motori di gioco – e i loro strumenti associati – generano e usano i loro propri dati di riflessione. Ci sono molti modi per farlo: Potete analizzare il vostro codice sorgente C/C++ per estrarre le informazioni sui tipi, come fa Blender. Puoi creare un linguaggio di descrizione dei dati separato e scrivere uno strumento per generare definizioni di tipo C++ e dati di riflessione da questo linguaggio. Puoi usare macro del preprocessore e template C++ per generare dati di riflessione in fase di esecuzione. E una volta che avete i dati di riflessione disponibili, ci sono innumerevoli modi per scrivere un serializzatore generico su di esso.
E’ chiaro che sto omettendo molti dettagli. In questo post, voglio solo mostrare che ci sono molti modi diversi per serializzare i dati, alcuni dei quali sono molto complessi. I programmatori semplicemente non discutono la serializzazione tanto quanto altri sistemi di motori, anche se la maggior parte degli altri sistemi si basano su di essa. Per esempio, dei 96 discorsi di programmazione tenuti alla GDC 2017, ho contato 31 discorsi sulla grafica, 11 sull’online, 10 sugli strumenti, 4 sull’IA, 3 sulla fisica, 2 sull’audio – ma solo uno che toccava direttamente la serializzazione.
Al minimo, cercate di avere un’idea di quanto saranno complesse le vostre esigenze. Se state facendo un gioco piccolo come Flappy Bird, con pochi asset, probabilmente non avete bisogno di pensare troppo alla serializzazione. Probabilmente puoi caricare le texture direttamente da PNG e andrà bene. Se avete bisogno di un formato binario compatto con compatibilità all’indietro, ma non volete sviluppare il vostro, date un’occhiata alle librerie di terze parti come Cereal o Boost.Serialization. Non credo che i Google Protocol Buffers siano l’ideale per serializzare le risorse di gioco, ma vale comunque la pena studiarli.
Scrivere un motore di gioco – anche uno piccolo – è una grande impresa. C’è molto altro che potrei dire a riguardo, ma per un post di questa lunghezza, questo è onestamente il consiglio più utile che posso pensare di dare: Lavorare in modo iterativo, resistere all’impulso di unificare un po’ il codice, e sapere che la serializzazione è un grande argomento in modo da poter scegliere una strategia appropriata. Nella mia esperienza, ognuna di queste cose può diventare un ostacolo se ignorata.
Adoro confrontare le note su queste cose, quindi sarei davvero interessato a sentire gli altri sviluppatori. Se avete scritto un motore, la vostra esperienza vi ha portato a qualcuna delle stesse conclusioni? E se non ne avete scritto uno, o ci state solo pensando, sono interessato anche ai vostri pensieri. Cosa considerate una buona risorsa da cui imparare? Quali parti ti sembrano ancora misteriose? Sentitevi liberi di lasciare un commento qui sotto o di contattarmi su Twitter!