A közelmúltban egy játékmotort írtam C++-ban. Egy kis mobiljátékot készítek vele, aminek a neve Hop Out. Itt egy klip, amit az iPhone 6 készülékemmel rögzítettem. (Hangot kikapcsolni!)

A Hop Out egy olyan játék, amivel játszani szeretnék: Retro arcade játékmenet 3D-s rajzfilmes megjelenéssel. A cél az, hogy minden pad színét megváltoztassuk, mint a Q*Bertben.
A Hop Out még fejlesztés alatt áll, de a motor, ami hajtja, kezd eléggé kiforrottá válni, ezért gondoltam, megosztok itt néhány tippet a motorfejlesztéssel kapcsolatban.
Miért akarsz játékmotort írni? Sokféle ok lehetséges:
- Barkácsoló vagy. Imádsz rendszereket építeni az alapoktól kezdve, és látni, ahogy életre kelnek.
- Még többet szeretnél tanulni a játékfejlesztésről. Én 14 évet töltöttem a játékiparban, és még mindig ismerkedem vele. Még abban sem voltam biztos, hogy tudnék-e motort írni a semmiből, mivel ez nagyban különbözik egy nagy stúdióban végzett programozói munka mindennapi feladataitól. Ki akartam deríteni.
- Az irányítást szereted. Kielégítő, hogy pontosan úgy szervezheted a kódot, ahogyan szeretnéd, és mindig tudod, hol van minden.
- A klasszikus játékmotorok, mint az AGI (1984), az id Tech 1 (1993), a Build (1995), és az olyan iparági óriások, mint a Unity és az Unreal, inspirálnak.
- Hiszed, hogy nekünk, a játékiparnak meg kellene próbálnunk demisztifikálni a motorfejlesztési folyamatot. Nem mintha elsajátítottuk volna a játékkészítés művészetét. Távolról sem! Minél jobban megvizsgáljuk ezt a folyamatot, annál nagyobb az esélyünk arra, hogy javítsunk rajta.
A 2017-es játékplatformok – mobil, konzol és PC – nagyon erősek, és sok tekintetben nagyon hasonlóak egymáshoz. A játékmotorok fejlesztése nem annyira a gyenge és egzotikus hardverekkel való küzdelemről szól, mint a múltban. Véleményem szerint sokkal inkább arról szól, hogy a saját magad által létrehozott komplexitással kell megküzdened. Könnyű szörnyeteget alkotni! Ezért ebben a bejegyzésben a tanácsok középpontjában az áll, hogy a dolgok kezelhetőek maradjanak. Három szakaszba rendeztem:
- Használj iteratív megközelítést
- Gondold meg kétszer, mielőtt túlságosan egységesíted a dolgokat
- Tudatában légy annak, hogy a szerializáció egy nagy téma
A tanácsok bármilyen játékmotorra érvényesek. Nem fogom megmondani, hogyan írj shadert, mi az az octree, vagy hogyan adj hozzá fizikát. Ezek olyan dolgok, amikről feltételezem, hogy már tudod, hogy tudnod kell – és ez nagyban függ attól, hogy milyen típusú játékot akarsz készíteni. Ehelyett szándékosan olyan pontokat választottam, amelyekről nem úgy tűnik, hogy széles körben elismerik vagy beszélnek róluk – ezek azok a pontok, amelyeket a legérdekesebbnek találok, amikor megpróbálok demisztifikálni egy témát.
Használj iteratív megközelítést
Az első tanácsom az, hogy gyorsan futtass valamit (bármit!), majd iterálj.
Ha lehetséges, kezdj egy mintaalkalmazással, amely inicializálja az eszközt és rajzol valamit a képernyőre. Az én esetemben letöltöttem az SDL-t, megnyitottam a Xcode-iOS/Test/TestiPhoneOS.xcodeproj, majd lefuttattam a testgles2 mintát az iPhone-omon.

Voilà! Volt egy szép forgó kockám az OpenGL ES 2.0 segítségével.
A következő lépésem az volt, hogy letöltöttem egy 3D modellt, amit valaki készített Marióról. Írtam egy gyors & piszkos OBJ fájl betöltőt – a fájlformátum nem olyan bonyolult – és meghekkeltem a mintaalkalmazást, hogy egy kocka helyett Mariót renderelje. Beépítettem az SDL_Image-et is, hogy segítsen a textúrák betöltésében.

Aztán implementáltam a dual-stick vezérlést Mario mozgatásához. (Kezdetben egy dual-stick shooter készítésén gondolkodtam. De nem Marióval.)

Ezután a csontváz-animációt akartam felfedezni, ezért megnyitottam a Blendert, modelleztem egy csápot, és egy kétcsontos csontvázzal rigeltem, ami ide-oda tekergett.
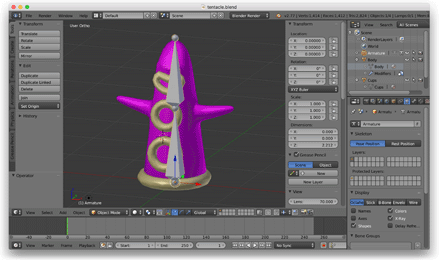
Az OBJ fájlformátumot ekkor elhagytam, és írtam egy Python szkriptet az egyéni JSON fájlok Blenderből történő exportálásához. Ezek a JSON fájlok a nyúzott hálót, a csontvázat és az animációs adatokat írták le. Ezeket a fájlokat egy C++ JSON könyvtár segítségével töltöttem be a játékba.

Amikor ez működött, visszamentem a Blenderbe, és kidolgozottabb karaktert készítettem. (Ez volt az első rigged 3D-s ember, amit valaha is készítettem. Elég büszke voltam rá.)

A következő néhány hónapban a következő lépéseket tettem:
- Megkezdtem a vektor- és mátrixfüggvények faktorálását a saját 3D matematikai könyvtáramba.
- Kicseréltem a
.xcodeproj-t egy CMake projektre. - Megkezdtem a motor futtatását Windowson és iOS-en is, mert szeretek Visual Studio-ban dolgozni.
- Megkezdtem a kód áthelyezését külön “motor” és “játék” könyvtárakba. Idővel ezeket még részletesebb könyvtárakra osztottam.
- Egy külön alkalmazást írtam, hogy a JSON fájljaimat bináris adatokká alakítsam, amelyeket a játék közvetlenül be tud tölteni.
- Végezetül eltávolítottam az összes SDL könyvtárat az iOS buildből. (A Windows build még mindig SDL-t használ.)
A lényeg a következő: Nem terveztem meg a motor architektúráját, mielőtt elkezdtem volna programozni. Ez egy tudatos döntés volt. Ehelyett csak megírtam a legegyszerűbb kódot, ami megvalósította a következő funkciót, aztán megnéztem a kódot, hogy lássam, milyen architektúra alakul ki természetesen. A “motorarchitektúra” alatt a játékmotort alkotó modulok halmazát, a modulok közötti függőségeket és az egyes modulokkal való interakcióra szolgáló API-t értem.
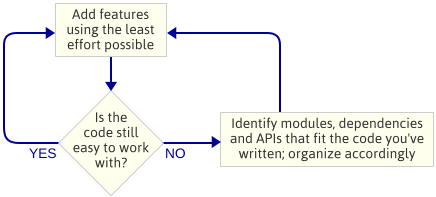
Ez egy iteratív megközelítés, mert kisebb eredményekre összpontosít. Jól működik egy játékmotor írásakor, mert az út minden egyes lépésénél van egy futó program. Ha valami rosszul megy, amikor egy új modulba faktorálod a kódot, mindig össze tudod hasonlítani a változtatásokat a korábban működő kóddal. Nyilvánvalóan feltételezem, hogy valamilyen forráskód-ellenőrzést használsz.
Azt gondolhatod, hogy sok idő megy veszendőbe ezzel a megközelítéssel, mivel mindig rossz kódot írsz, amit később ki kell takarítani. De a legtöbb tisztítás az egyik .cpp fájlból a másikba való kód áthelyezéséből, függvénydeklarációk .h fájlokba való kivonásából, vagy hasonlóan egyszerű változtatásokból áll. Annak eldöntése, hogy hova kerüljenek a dolgok, a nehéz rész, és ezt könnyebb megtenni, ha a kód már létezik.
Azzal érvelnék, hogy az ellenkező megközelítéssel több időt pazarolunk el: Túlságosan keményen próbálkozni egy olyan architektúrával, amely mindent megtesz, amire úgy gondolod, hogy idő előtt szükséged lesz. Két kedvenc cikkem a túlmérnökösködés veszélyeiről: Tomasz Dąbrowski: The Vicious Circle of Generalization és Joel Spolsky: Don’t Let Architecture Astronauts Scare You.
Nem azt mondom, hogy soha ne oldjunk meg egy problémát papíron, mielőtt kódban kezelnénk. Azt sem mondom, hogy ne döntsd el előre, milyen funkciókat szeretnél. Én például kezdettől fogva tudtam, hogy azt akarom, hogy a motorom az összes eszközt egy háttérszálban töltse be. Csak addig nem próbáltam megtervezni vagy megvalósítani ezt a funkciót, amíg a motorom be nem töltött néhány eszközt.
Az iteratív megközelítés sokkal elegánsabb architektúrát eredményezett, mint amilyet egy üres papírlapra meredve valaha is megálmodtam volna. A motorom iOS buildje most már 100%-ban eredeti kód, beleértve az egyéni matematikai könyvtárat, a konténersablonokat, a reflexiós/sorializációs rendszert, a renderelési keretrendszert, a fizikát és a hangkeverőt. Mindegyik modul megírására megvolt az okom, de lehet, hogy te nem tartod szükségesnek, hogy mindezeket magad írd meg. Rengeteg nagyszerű, szabadon licencelt nyílt forráskódú könyvtár van, amit ehelyett megfelelőnek találhatsz a motorodhoz. A GLM, a Bullet Physics és az STB fejlécek csak néhány érdekes példa.
Gondold meg kétszer, mielőtt túlságosan egységesíted a dolgokat
Programozóként igyekszünk elkerülni a kódduplikációt, és szeretjük, ha a kódunk egységes stílust követ. Szerintem azonban jó, ha nem hagyjuk, hogy ezek az ösztönök minden döntést felülírjanak.
Egyszer-egyszer ellenállni a DRY-elvnek
Hogy egy példát mondjak, a motorom több “okosmutatós” sablonosztályt tartalmaz, hasonló szellemben, mint az std::shared_ptr. Mindegyik segít megelőzni a memóriaszivárgást azáltal, hogy egy nyers mutató körüli burkolatként szolgál.
-
Owned<>dinamikusan allokált objektumokhoz, amelyeknek egyetlen tulajdonosa van. -
Reference<>a referenciaszámlálást használja, hogy egy objektumnak több tulajdonosa lehessen. -
audio::AppOwned<>a hangkeverőn kívüli kód használja. Lehetővé teszi a játékrendszerek számára, hogy olyan objektumokat birtokoljanak, amelyeket az audiomixer használ, például az éppen lejátszott hangot. -
audio::AudioHandle<>az audiomixer belső referenciaszámláló rendszerét használja.
Úgy tűnhet, hogy néhány ilyen osztály megismétli a többiek funkcióit, megsértve ezzel a DRY (Don’t Repeat Yourself) elvet. Valóban, a fejlesztés korábbi szakaszában megpróbáltam a meglévő Reference<> osztályt újra felhasználni, amennyire csak lehetett. Azonban rájöttem, hogy egy audio objektum élettartamát speciális szabályok szabályozzák: Ha egy audió hang befejezte egy minta lejátszását, és a játék nem rendelkezik mutatóval az adott hangra, a hang azonnal törlésre kerülhet a sorba. Ha a játék rendelkezik mutatóval, akkor a hangobjektumot nem szabad törölni. Ha pedig a játék rendelkezik mutatóval, de a mutató tulajdonosa a hang befejezése előtt megsemmisül, akkor a hangot törölni kell. Ahelyett, hogy bonyolultabbá tenném a Reference<>-t, úgy döntöttem, hogy praktikusabb lenne helyette külön sablonosztályokat bevezetni.
95%-ban a meglévő kód újrafelhasználása a legjobb megoldás. De ha elkezdjük bénultnak érezni magunkat, vagy azon kapjuk magunkat, hogy bonyolultabbá teszünk valamit, ami korábban egyszerű volt, kérdezzük meg magunktól, hogy a kódbázisban valaminek valójában két dolognak kellene-e lennie.
Ez rendben van, hogy különböző hívási konvenciókat használunk
Egy dolog, amit nem szeretek a Java-ban, hogy arra kényszerít, hogy minden függvényt egy osztályon belül definiáljunk. Ez szerintem nonszensz. Lehet, hogy a kódod így konzisztensebbnek tűnik, de túlmérnökösködésre ösztönöz, és nem alkalmas a korábban leírt iteratív megközelítésre.
A C++ motoromban egyes függvények osztályokhoz tartoznak, mások nem. Például minden ellenség a játékban egy osztály, és az ellenség viselkedésének nagy része az osztályon belül van implementálva, ahogy azt valószínűleg elvárnád. Másrészt a gömböntések az én motoromban a sphereCast(), egy physics névtérben lévő függvény meghívásával történnek. A sphereCast() nem tartozik semmilyen osztályhoz – csak a physics modul része. Van egy build rendszerem, amely kezeli a modulok közötti függőségeket, ami elég jól rendszerezi a kódot számomra. Ha ezt a függvényt egy tetszőleges osztályba csomagoljuk, az nem javít a kódszervezésen semmilyen értelmes módon.
Aztán ott van a dinamikus diszpécser, ami a polimorfizmus egy formája. Gyakran van szükségünk arra, hogy egy objektum függvényét úgy hívjuk meg, hogy nem ismerjük az objektum pontos típusát. A C++ programozó első ösztöne az, hogy definiál egy absztrakt alaposztályt virtuális függvényekkel, majd felülírja ezeket a függvényeket egy származtatott osztályban. Ez jogos, de ez csak egy technika. Vannak más dinamikus diszpécser technikák is, amelyek nem vezetnek be annyi extra kódot, vagy más előnyökkel járnak:
- A C++11 bevezette a
std::function-t, amely egy kényelmes módja a callback függvények tárolásának. Lehetőség van astd::functionsaját verziójának megírására is, amelybe kevésbé fájdalmas belelépni a hibakeresőben. - Sok callback függvény megvalósítható egy pár mutatóval: Egy függvénymutató és egy átláthatatlan argumentum. Ez csak egy explicit castot igényel a callback függvényen belül. Ezt sokszor láthatjuk tiszta C könyvtárakban.
- Néha a mögöttes típus valóban ismert a fordítási időben, és a függvényhívást minden további futásidejű overhead nélkül le lehet kötni. A Turf, egy könyvtár, amit a játékmotoromban használok, sokat támaszkodik erre a technikára. Lásd például
turf::Mutex. Ez csak egytypedefegy platform-specifikus osztály felett. - Néha a legegyszerűbb megközelítés az, ha magad készítesz és tartasz fenn egy táblázatot a nyers függvénymutatókról. Ezt a megközelítést használtam a hangkeverő és szerializációs rendszeremben. A Python-értelmező is nagymértékben használja ezt a technikát, amint azt alább említjük.
- A függvénymutatókat akár egy hash-táblában is tárolhatjuk, a függvényneveket kulcsként használva. Ezt a technikát használom a bemeneti események, például a multitouch események elküldésére. Ez része a játékbemenetek rögzítésére és visszajátszására szolgáló stratégiának egy visszajátszási rendszerrel.
A dinamikus diszpécser egy nagy téma. Csak a felszínt karcolom, hogy megmutassam, hogy sokféleképpen lehet megvalósítani. Minél több bővíthető, alacsony szintű kódot írsz – ami egy játékmotorban gyakori – annál több alternatívát fogsz felfedezni. Ha nem vagy hozzászokva ehhez a fajta programozáshoz, a Python interpreter, amely C nyelven íródott, kiváló forrás a tanuláshoz. Erőteljes objektummodellt valósít meg: Minden PyObject egy PyTypeObject-re mutat, és minden PyTypeObject tartalmaz egy táblázatnyi függvénymutatót a dinamikus diszpécserhez. Az Új típusok definiálása című dokumentum jó kiindulópont, ha rögtön bele akarsz ugrani.
Tudd, hogy a szerializáció nagy téma
A szerializáció a futásidejű objektumok bájtsorozattá és bájtsorozatból való átalakítása. Más szóval az adatok mentése és betöltése.
Sok, ha nem a legtöbb játékmotor esetében a játék tartalma különböző szerkeszthető formátumokban, például .png, .json, .blend vagy szabadalmaztatott formátumokban készül, majd végül olyan platform-specifikus játékformátumokba konvertálódik, amelyeket a motor gyorsan be tud tölteni. Az utolsó alkalmazást ebben a csővezetékben gyakran “főzőnek” nevezik. A cooker integrálható egy másik eszközbe, vagy akár több gépre is szétosztható. Általában a cookert és számos eszközt magával a játékmotorral együtt fejlesztik és karbantartják.
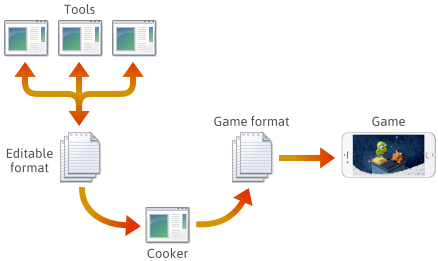
Az ilyen csővezeték felállításakor a fájlformátum kiválasztása az egyes fázisokban az Öntől függ. Meghatározhatsz néhány saját fájlformátumot, és ezek a formátumok fejlődhetnek, ahogy a motor funkcióit bővíted. Ahogy fejlődnek, szükség lehet arra, hogy bizonyos programok kompatibilisek maradjanak a korábban elmentett fájlokkal. Nem számít, hogy milyen formátumot használsz, végül C++-ban kell majd szerializálnod.
A szerializálás megvalósításának számtalan módja van C++-ban. Az egyik meglehetősen kézenfekvő mód az, hogy load és save függvényeket adunk a szerializálni kívánt C++ osztályokhoz. A visszafelé kompatibilitást úgy érhetjük el, hogy a fájl fejlécében tárolunk egy verziószámot, majd ezt a számot minden load függvénybe átadjuk. Ez működik, bár a kód karbantartása nehézkessé válhat.
void load(InStream& in, u32 fileVersion) { // Load expected member variables in >> m_position; in >> m_direction; // Load a newer variable only if the file version being loaded is 2 or greater if (fileVersion >= 2) { in >> m_velocity; } }
A reflexió kihasználásával – pontosabban a C++ típusok elrendezését leíró futásidejű adatok létrehozásával – rugalmasabb, kevésbé hibás szerializációs kódot írhatunk. Egy gyors ötletért, hogy a reflexió hogyan segíthet a szerializálásban, nézd meg, hogyan csinálja ezt a Blender, egy nyílt forráskódú projekt.
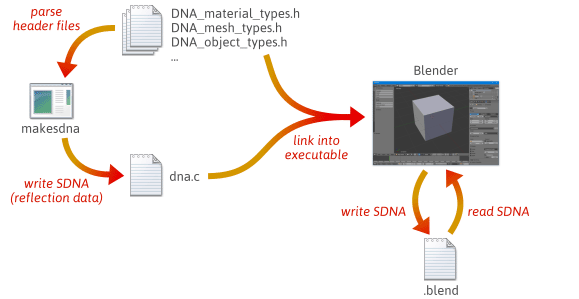
Amikor a Blendert forráskódból építed, sok lépés történik. Először egy makesdna nevű egyéni segédprogramot fordítanak le és futtatnak le. Ez a segédprogram elemez egy sor C fejlécfájlt a Blender forrásfájában, majd egy SDNA néven ismert egyéni formátumban kiad egy kompakt összefoglalót a benne definiált összes C típusról. Ezek az SDNA adatok tükrözési adatokként szolgálnak. Az SDNA-t ezután magába a Blenderbe linkeli, és elmenti minden .blend fájlba, amit a Blender ír. Ettől kezdve, amikor a Blender betölt egy .blend fájlt, összehasonlítja a .blend fájl SDNA-ját az aktuális verzióba futásidőben belinkelt SDNA-val, és általános szerializációs kódot használ az esetleges különbségek kezelésére. Ez a stratégia lenyűgöző mértékű visszafelé és előre kompatibilitást biztosít a Blender számára. Az 1.0-s fájlok továbbra is betölthetők a Blender legújabb verziójában, és az új .blend fájlok betölthetők a régebbi verziókban.
A Blenderhez hasonlóan sok játékmotor – és a hozzájuk kapcsolódó eszközök – saját reflexiós adatokat generálnak és használnak. Ennek számos módja van: A Blenderhez hasonlóan elemezheti a saját C/C++ forráskódját a típusinformációk kinyeréséhez. Létrehozhatsz egy külön adatleíró nyelvet, és írhatsz egy eszközt, amely ebből a nyelvből C++ típusdefiníciókat és reflexiós adatokat generál. Használhat preprocesszor makrókat és C++ sablonokat a reflexiós adatok futásidejű generálásához. És ha már rendelkezésre állnak a reflexiós adatok, számtalan módja van annak, hogy általános szerializálót írjunk rá.
Láthatóan sok részletet kihagyok. Ebben a bejegyzésben csak azt akarom megmutatni, hogy sokféle módja van az adatok szerializálásának, amelyek közül néhány nagyon összetett. A programozók csak nem beszélnek annyit a szerializálásról, mint más motoros rendszerekről, pedig a legtöbb más rendszer erre támaszkodik. Például a GDC 2017-en tartott 96 programozási előadásból 31 előadást számoltam meg a grafikáról, 11-et az online, 10-et az eszközökről, 4-et az AI-ról, 3-at a fizikáról, 2-őt az audióról – de csak egyet, amely közvetlenül érintette a szerializálást.
Minimum próbálj meg elképzelést szerezni arról, hogy milyen összetett igényeid lesznek. Ha egy olyan apró játékot készítesz, mint a Flappy Bird, csak néhány eszközzel, akkor valószínűleg nem kell túl sokat gondolkodnod a szerializáción. Valószínűleg a textúrákat közvetlenül PNG-ből is betöltheted, és minden rendben lesz. Ha kompakt, visszafelé kompatibilis bináris formátumra van szükséged, de nem akarsz sajátot fejleszteni, nézz körül az olyan harmadik féltől származó könyvtárakban, mint a Cereal vagy a Boost.Serialization. Nem hiszem, hogy a Google Protocol Buffers ideális játékeszközök szerializálására, de ettől függetlenül érdemes tanulmányozni őket.
Egy játékmotor megírása – még ha kicsi is – nagy vállalkozás. Sok mindent mondhatnék még erről, de egy ilyen hosszúságú posztban őszintén szólva ez a leghasznosabb tanács, ami eszembe jutott: Dolgozz iteratívan, állj ellen a késztetésnek, hogy egy kicsit egységesítsd a kódot, és tudd, hogy a szerializáció egy nagy téma, hogy megfelelő stratégiát választhass. Tapasztalatom szerint ezek mindegyike buktatóvá válhat, ha figyelmen kívül hagyják.
Szeretem összehasonlítani a jegyzeteimet ezekkel a dolgokkal kapcsolatban, ezért nagyon érdekelne, ha más fejlesztők véleményét is hallanám. Ha írtál már motort, a tapasztalataid ugyanezekre a következtetésekre vezettek? És ha még nem írtál, vagy csak gondolkodsz rajta, akkor is érdekelnek a gondolataid. Mit tartasz jó forrásnak, amiből tanulhatsz? Mely részek tűnnek még mindig rejtélyesnek számodra? Nyugodtan hagyj egy megjegyzést alább, vagy írj nekem Twitteren!