Viime aikoina olen kirjoittanut pelimoottoria C++:lla. Teen sillä pientä mobiilipeliä nimeltä Hop Out. Tässä on pätkä, joka on kuvattu iPhone 6:lla. (Unmute for sound!)

Hop Out on juuri sellainen peli, jota haluan pelata: Retro arcade -pelattavuus 3D-sarjakuvamaisella ulkoasulla. Tavoitteena on vaihtaa jokaisen padin väriä, kuten Q*Bertissä.
Hop Out on vielä kehitteillä, mutta sitä pyörittävä moottori alkaa olla jo melko kypsä, joten ajattelin jakaa tässä muutamia vinkkejä moottorin kehittämisestä.
Miksi haluaisit kirjoittaa pelimoottorin? Mahdollisia syitä on monia:
- Olet puuhastelija. Rakastat rakentaa järjestelmiä alusta alkaen ja nähdä niiden heräävän eloon.
- Haluat oppia lisää pelinkehityksestä. Vietin 14 vuotta pelialalla ja olen yhä selvittämässä sitä. En ollut edes varma, voisinko kirjoittaa pelimoottorin tyhjästä, koska se eroaa huomattavasti ison studion ohjelmointityön päivittäisistä velvollisuuksista. Halusin ottaa siitä selvää.
- Tykkäät hallita. On tyydyttävää järjestää koodi juuri haluamallasi tavalla ja tietää, missä kaikki on koko ajan.
- Olet inspiroitunut klassisista pelimoottoreista, kuten AGI (1984), id Tech 1 (1993), Build (1995) ja alan jättiläisistä, kuten Unitystä ja Unrealista.
- Olet sitä mieltä, että meidän, peliteollisuuden, pitäisi pyrkiä demystifioimaan moottorin kehitystyöprosessi. Ei ole niin, että hallitsisimme pelien tekemisen taidon. Kaukana siitä! Mitä enemmän tutkimme tätä prosessia, sitä suuremmat mahdollisuutemme ovat parantaa sitä.
Vuoden 2017 pelialustat – mobiili, konsoli ja PC – ovat hyvin tehokkaita ja monin tavoin melko samanlaisia keskenään. Pelimoottoreiden kehittämisessä ei ole niinkään kyse kamppailusta heikon ja eksoottisen laitteiston kanssa, kuten aiemmin. Mielestäni kyse on pikemminkin kamppailusta itse luodun monimutkaisuuden kanssa. On helppoa luoda hirviö! Siksi tämän viestin neuvot keskittyvät siihen, että asiat pysyvät hallittavina. Olen järjestänyt sen kolmeen osaan:
- Käytä iteratiivista lähestymistapaa
- Harkitse kahdesti ennen kuin yhtenäistät asioita liikaa
- Ole tietoinen siitä, että sarjallistaminen on iso aihe
Nämä neuvot pätevät mihin tahansa pelimoottoriin. En aio kertoa sinulle, kuinka kirjoittaa shader, mikä on octree tai kuinka lisätä fysiikkaa. Nuo ovat sellaisia asioita, jotka oletan sinun jo tietävän, että sinun pitäisi osata – ja se riippuu pitkälti siitä, millaisen pelin haluat tehdä. Sen sijaan olen tarkoituksella valinnut kohtia, joita ei tunnu yleisesti tunnustettavan tai joista ei puhuta – tällaiset kohdat ovat mielestäni kiinnostavimpia, kun yritän demystifioida aihetta.
Käytä iteratiivista lähestymistapaa
Ensimmäinen neuvoni on saada jotain (mitä tahansa!) nopeasti käyntiin, ja sen jälkeen iteroida.
Jos mahdollista, aloita esimerkkisovelluksella, joka alustaa laitteen ja piirtää jotain näytölle. Omassa tapauksessani latasin SDL:n, avasin Xcode-iOS/Test/TestiPhoneOS.xcodeproj ja ajoin sitten testgles2-näytteen iPhonellani.

Voilà! Minulla oli ihana pyörivä kuutio OpenGL ES 2.0:n avulla.
Seuraavaksi latasin jonkun tekemän 3D-mallin Mariosta. Kirjoitin nopean & likaisen OBJ-tiedoston lataajan – tiedostomuoto ei ole kovin monimutkainen – ja hakkasin esimerkkisovelluksen renderöimään Marion kuution sijaan. Integroin myös SDL_Imagen auttamaan tekstuurien lataamisessa.

Sitten toteutin dual-stick-ohjaimet Marion liikuttamiseksi. (Alussa harkitsin dual-stick-räiskintäpelin tekemistä. En kuitenkaan Marion kanssa.)

Seuraavaksi halusin tutkia luurankoanimaatiota, joten avasin Blenderin, mallinsin lonkeron ja riggasin sen kahden luun luurangolla, joka heilui edestakaisin.
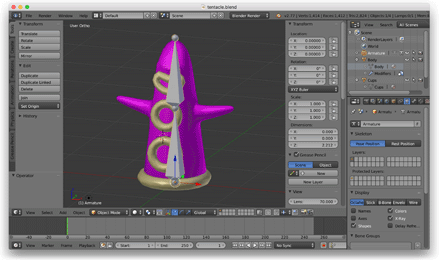
Hylkäsin OBJ-tiedostomuodon ja kirjoitin Python-skriptin, jonka avulla voitiin viedä Blenderistä mukautettuja JSON-tiedostoja. Nämä JSON-tiedostot kuvasivat nyljetyn meshin, luurangon ja animaatiotiedot. Latasin nämä tiedostot peliin C++ JSON-kirjaston avulla.

Kun tämä toimi, palasin Blenderiin ja tein kehittyneemmän hahmon. (Tämä oli ensimmäinen rigattu 3D-ihminen, jonka koskaan loin. Olin aika ylpeä hänestä.)

Seuraavien kuukausien aikana otin seuraavat askeleet:
- Aloitin vektori- ja matriisifunktioiden faktoroinnin omaan 3D-matematiikkakirjastooni.
- Vaihdoin
.xcodeprojCMake-projektiin. - Sain moottorin toimimaan sekä Windowsissa että iOS:ssä, koska tykkään työskennellä Visual Studiossa.
- Aloitin koodin siirtämisen erillisiin ”moottori”- ja ”peli”-kirjastoihin. Ajan mittaan jaoin nämä vielä rakeisempiin kirjastoihin.
- Kirjoitin erillisen sovelluksen, joka muuntaa JSON-tiedostoni binääridataksi, jota peli voi ladata suoraan.
- Poistin lopulta kaikki SDL-kirjastot iOS-rakennuksesta. (Windows build käyttää edelleen SDL:ää.)
Piste on: En suunnitellut moottorin arkkitehtuuria ennen kuin aloitin ohjelmoinnin. Tämä oli tietoinen valinta. Sen sijaan kirjoitin vain yksinkertaisimman koodin, joka toteutti seuraavan ominaisuuden, ja sitten katsoin koodia nähdäkseni, millainen arkkitehtuuri syntyi luonnollisesti. Moottorin arkkitehtuurilla tarkoitan pelimoottorin muodostavien moduulien joukkoa, näiden moduulien välisiä riippuvuuksia ja API:ta, jolla kunkin moduulin kanssa toimitaan vuorovaikutuksessa.
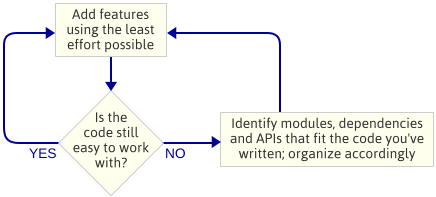
Tämä on iteratiivinen lähestymistapa, koska siinä keskitytään pienempiin tuotoksiin. Se toimii hyvin pelimoottoria kirjoitettaessa, koska jokaisessa vaiheessa matkan varrella on käynnissä oleva ohjelma. Jos jokin menee pieleen, kun olet sisällyttämässä koodia uuteen moduuliin, voit aina verrata muutoksia aiemmin toimineeseen koodiin. Oletan tietenkin, että käytät jonkinlaista lähdekoodinhallintaa.
Saatat ajatella, että tällä lähestymistavalla menee paljon aikaa hukkaan, koska kirjoitat aina huonoa koodia, joka pitää myöhemmin siivota. Mutta suurin osa siivoamisesta on kuitenkin koodin siirtämistä .cpp-tiedostosta toiseen, funktioiden julistusten purkamista .h-tiedostoihin tai yhtä suoraviivaisia muutoksia. Vaikeinta on päättää, minne asiat pitäisi siirtää, ja se on helpompi tehdä, kun koodi on jo olemassa.
Väittäisin, että päinvastaiseen lähestymistapaan tuhlataan enemmän aikaa: Yritetään liian kovasti keksiä arkkitehtuuri, joka tekee kaiken, mitä luulet tarvitsevasi etukäteen. Kaksi suosikkiartikkeliani liiallisen suunnittelun vaaroista ovat Tomasz Dąbrowskin kirjoittama The Vicious Circle of Generalization (Yleistämisen noidankehä) ja Joel Spolskyn kirjoittama Don’t Let Architecture Astronauts Scare You (Älä anna arkkitehtuurin astronauttien pelotella sinua).
En sano, että ongelmaa ei saisi koskaan ratkoa paperilla, ennen kuin siihen tartutaan koodissa. En myöskään sano, että sinun ei pitäisi päättää etukäteen, mitä ominaisuuksia haluat. Tiesin esimerkiksi alusta asti, että halusin moottorini lataavan kaikki assetit taustasäikeessä. En vain yrittänyt suunnitella tai toteuttaa tuota ominaisuutta ennen kuin moottori todella latasi ensin joitain assetteja.
Iteratiivinen lähestymistapa on antanut minulle paljon tyylikkäämmän arkkitehtuurin kuin olisin ikinä voinut haaveilla tuijottamalla tyhjää paperia. Moottorini iOS-rakennus on nyt 100-prosenttisesti alkuperäistä koodia, mukaan lukien räätälöity matematiikkakirjasto, konttipohjat, heijastus-/sarjalointijärjestelmä, renderöintikehys, fysiikka- ja äänimikseri. Minulla oli syitä kirjoittaa jokainen näistä moduuleista, mutta sinun ei välttämättä tarvitse kirjoittaa kaikkia näitä asioita itse. Sen sijaan on paljon loistavia, luvallisesti lisensoituja avoimen lähdekoodin kirjastoja, jotka saattaisivat sopia moottorillesi. GLM, Bullet Physics ja STB-otsikot ovat vain muutamia mielenkiintoisia esimerkkejä.
Harkitse kahdesti ennen kuin yhtenäistät asioita liikaa
Ohjelmoijina pyrimme välttämään koodin päällekkäisyyksiä, ja pidämme siitä, että koodimme noudattaa yhtenäistä tyyliä. Mielestäni on kuitenkin hyvä olla antamatta näiden vaistojen ohittaa kaikkia päätöksiä.
Vastusta DRY-periaatteesta silloin tällöin
Esimerkiksi moottorissani on useita ”älykkään osoittimen” malliluokkia, jotka ovat hengeltään samanlaisia kuin std::shared_ptr. Jokainen niistä auttaa estämään muistivuodot toimimalla kääreenä raa’an osoittimen ympärillä.
-
Owned<>on tarkoitettu dynaamisesti allokoituja objekteja varten, joilla on yksi omistaja. -
Reference<>käyttää viittauslaskentaa salliakseen, että objektilla voi olla useampi omistaja. -
audio::AppOwned<>käytetään audiosekoittimen ulkopuolisessa koodissa. Sen avulla pelijärjestelmät voivat omistaa äänimikserin käyttämiä objekteja, kuten parhaillaan soivan äänen. -
audio::AudioHandle<>käyttää äänimikserin sisäistä viittauslaskentajärjestelmää.
Saattaa näyttää siltä, että jotkin näistä luokista toistavat toistensa toiminnallisuutta, mikä rikkoo DRY-periaatetta (Don’t Repeat Yourself). Kehityksen aikaisemmassa vaiheessa yritin tosiaan käyttää olemassa olevaa Reference<>-luokkaa uudelleen niin paljon kuin mahdollista. Huomasin kuitenkin, että ääniobjektin elinikää säätelevät erityiset säännöt: Jos ääniääni on lopettanut näytteen soittamisen, eikä pelissä ole osoitinta kyseiseen ääneen, ääni voidaan asettaa jonoon poistettavaksi välittömästi. Jos pelillä on osoitin, ääniobjektia ei saa poistaa. Ja jos pelillä on osoitin, mutta osoittimen omistaja tuhoutuu ennen kuin ääni on päättynyt, ääni on peruutettava. Sen sijaan, että olisin lisännyt monimutkaisuutta Reference<>:een, päätin, että on käytännöllisempää ottaa sen sijaan käyttöön erilliset malliluokat.
95% ajasta olemassa olevan koodin uudelleenkäyttö on paras tapa. Mutta jos alat tuntea olosi lamaantuneeksi tai huomaat lisääväsi monimutkaisuutta johonkin, joka oli kerran yksinkertaista, kysy itseltäsi, pitäisikö koodipohjassa jonkin asian todella olla kahta asiaa.
Ei haittaa käyttää erilaisia kutsukäytäntöjä
Yksi asia, josta en pidä Javassa, on se, että se pakottaa määrittelemään jokaisen funktion luokan sisällä. Se on mielestäni hölynpölyä. Se saattaa saada koodin näyttämään johdonmukaisemmalta, mutta se myös rohkaisee liialliseen suunnitteluun eikä sovellu hyvin aiemmin kuvaamalleni iteratiiviselle lähestymistavalle.
C++-moottorissani jotkut funktiot kuuluvat luokkiin ja jotkut eivät. Esimerkiksi jokainen vihollinen pelissä on luokka, ja suurin osa vihollisen käyttäytymisestä on toteutettu tuon luokan sisällä, kuten luultavasti oletat. Toisaalta moottorissani pallonheitto suoritetaan kutsumalla sphereCast(), joka on physics-nimiavaruuden funktio. sphereCast() ei kuulu mihinkään luokkaan – se on vain osa physics-moduulia. Minulla on build-järjestelmä, joka hallinnoi moduulien välisiä riippuvuuksia, mikä pitää koodin riittävän hyvin järjestyksessä. Tämän funktion kietominen mielivaltaisen luokan sisään ei paranna koodin organisointia millään mielekkäällä tavalla.
Sitten on vielä dynaaminen dispatch, joka on eräs polymorfismin muoto. Meidän on usein kutsuttava funktiota objektille tietämättä kyseisen objektin tarkkaa tyyppiä. C++-ohjelmoijan ensimmäinen vaisto on määritellä abstrakti perusluokka, jossa on virtuaalifunktioita, ja sitten ohittaa nämä funktiot johdetussa luokassa. Se on oikein, mutta se on vain yksi tekniikka. On muitakin dynaamisia lähetystekniikoita, jotka eivät tuo yhtä paljon ylimääräistä koodia tai jotka tuovat muita etuja:
- C++11 esitteli
std::function, joka on kätevä tapa tallentaa callback-funktioita. On myös mahdollista kirjoittaa oma versiostd::function:sta, johon on vähemmän tuskallista astua debuggerissa. - Monet callback-funktiot voidaan toteuttaa osoitinparilla: Funktion osoitin ja läpinäkymätön argumentti. Se vaatii vain eksplisiittisen castin callback-funktion sisällä. Tätä näkee paljon puhtaissa C-kirjastoissa.
- Joskus taustalla oleva tyyppi on itse asiassa tiedossa kääntämisaikana, ja voit sitoa funktiokutsun ilman ylimääräistä ajonaikaista ylikuormitusta. Turf, kirjasto, jota käytän pelimoottorissani, luottaa tähän tekniikkaan paljon. Katso esimerkiksi
turf::Mutex. Se on vaintypedefalustakohtaisen luokan yli. - Joskus suoraviivaisin lähestymistapa on rakentaa ja ylläpitää itse raakafunktio-osoittimien taulukko. Käytin tätä lähestymistapaa äänimikserissäni ja serialisointijärjestelmässäni. Myös Python-tulkki käyttää tätä tekniikkaa ahkerasti, kuten jäljempänä mainitaan.
- Voit jopa tallentaa funktio-osoittimet hash-taulukkoon käyttäen funktioiden nimiä avaimina. Käytän tätä tekniikkaa syöttötapahtumien, kuten multitouch-tapahtumien, lähettämiseen. Se on osa strategiaa, jolla tallennetaan pelin syötteitä ja toistetaan niitä toistosysteemin avulla.
Dynaaminen lähetys on iso aihe. Raaputan vain pintaa osoittaakseni, että on monia tapoja saavuttaa se. Mitä enemmän kirjoitat laajennettavaa matalan tason koodia – mikä on yleistä pelimoottorissa – sitä enemmän huomaat tutkivasi vaihtoehtoja. Jos et ole tottunut tällaiseen ohjelmointiin, Python-tulkki, joka on kirjoitettu C-kielellä, on erinomainen resurssi, josta voit oppia. Se toteuttaa tehokkaan objektimallin: Jokainen PyObject osoittaa PyTypeObject:een, ja jokainen PyTypeObject sisältää taulukon funktio-osoittimia dynaamista lähetystä varten. Dokumentti Defining New Types (Uusien tyyppien määrittely) on hyvä lähtökohta, jos haluat hypätä suoraan sisään.
Ole tietoinen siitä, että sarjallistaminen on iso aihe
Serialisointi on suoritusaikaisten objektien muuntamista tavujoukoksi ja tavujoukosta. Toisin sanoen datan tallentaminen ja lataaminen.
Monille ellei useimmille pelimoottoreille pelisisältö luodaan erilaisissa muokattavissa formaateissa, kuten .png, .json, .blend tai omissa formaateissa, ja muunnetaan sitten lopulta alustakohtaisiin pelimuotoihin, joita moottori voi ladata nopeasti. Tämän putken viimeistä sovellusta kutsutaan usein ”keittimeksi”. Keitin voidaan integroida toiseen työkaluun tai se voidaan jopa jakaa useille koneille. Yleensä cookeria ja useita työkaluja kehitetään ja ylläpidetään yhdessä itse pelimoottorin kanssa.
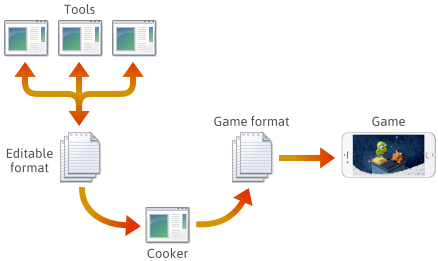
Tällaista putkea perustettaessa tiedostomuodon valinta kussakin vaiheessa on sinun päätettävissäsi. Saatat määritellä joitakin omia tiedostomuotoja, ja nämä muodot saattavat kehittyä, kun moottorin ominaisuuksia lisätään. Niiden kehittyessä saattaa olla tarpeen pitää tietyt ohjelmat yhteensopivina aiemmin tallennettujen tiedostojen kanssa. Olipa tiedostomuoto mikä tahansa, sinun on viime kädessä serialisoitava se C++:lla.
On olemassa lukemattomia tapoja toteuttaa serialisointi C++:ssa. Yksi melko ilmeinen tapa on lisätä load– ja save-funktioita C++-luokkiin, jotka haluat serialisoida. Voit saavuttaa taaksepäin yhteensopivuuden tallentamalla versionumeron tiedoston otsikkoon ja siirtämällä tämän numeron jokaiseen load-funktioon. Tämä toimii, vaikka koodin ylläpidosta voi tulla hankalaa.
void load(InStream& in, u32 fileVersion) { // Load expected member variables in >> m_position; in >> m_direction; // Load a newer variable only if the file version being loaded is 2 or greater if (fileVersion >= 2) { in >> m_velocity; } }
Serialisointikoodia on mahdollista kirjoittaa joustavammin ja vähemmän virhealttiisti hyödyntämällä heijastusta – tarkemmin sanottuna luomalla ajonaikaista dataa, joka kuvaa C++-tyyppien asettelua. Saat nopean käsityksen siitä, miten heijastus voi auttaa sarjallistamisessa, katsomalla, miten Blender, avoimen lähdekoodin projekti, tekee sen.
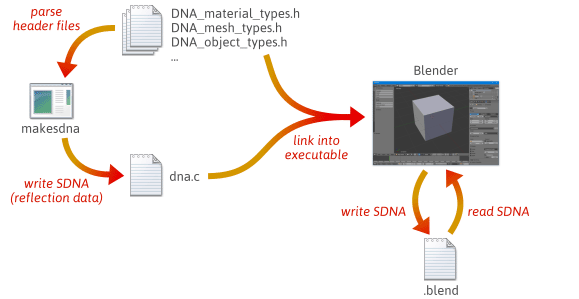
Kun rakennat Blenderin lähdekoodista, tapahtuu monia vaiheita. Ensin käännetään ja ajetaan oma apuohjelma nimeltä makesdna. Tämä apuohjelma jäsentää joukon Blenderin lähdepuussa olevia C-otsikkotiedostoja ja tuottaa sitten kompaktin yhteenvedon kaikista niissä määritellyistä C-tyypeistä mukautetussa muodossa, joka tunnetaan nimellä SDNA. Tämä SDNA-tieto toimii heijastustietona. SDNA linkitetään sitten itse Blenderiin ja tallennetaan jokaisen .blend-tiedoston mukana, jonka Blender kirjoittaa. Tästä lähtien aina kun Blender lataa .blend-tiedoston, se vertaa .blend-tiedoston SDNA:ta ajoaikana nykyiseen versioon linkitettyyn SDNA:han ja käyttää geneeristä serialisointikoodia käsittelemään mahdolliset erot. Tämä strategia antaa Blenderille vaikuttavan yhteensopivuuden taaksepäin ja eteenpäin. Voit edelleen ladata 1.0-tiedostoja Blenderin uusimmassa versiossa, ja uudet .blend-tiedostot voidaan ladata vanhemmissa versioissa.
Blenderin tavoin monet pelimoottorit – ja niihin liittyvät työkalut – tuottavat ja käyttävät omia heijastustietojaan. Siihen on monia tapoja: Voit analysoida omaa C/C++-lähdekoodiasi poimimaan tyyppitietoja, kuten Blender tekee. Voit luoda erillisen datan kuvauskielen ja kirjoittaa työkalun, joka tuottaa C++-tyyppimäärittelyt ja heijastustiedot tästä kielestä. Voit käyttää esiprosessorimakroja ja C++-malleja heijastustietojen tuottamiseen ajon aikana. Ja kun sinulla on heijastusdataa saatavilla, on lukemattomia tapoja kirjoittaa geneerinen sarjallistin sen päälle.
Yksiselitteisesti jätän pois paljon yksityiskohtia. Tässä viestissä haluan vain osoittaa, että on olemassa monia erilaisia tapoja serialisoida dataa, joista osa on hyvin monimutkaisia. Ohjelmoijat eivät vain keskustele serialisoinnista yhtä paljon kuin muista moottorijärjestelmistä, vaikka useimmat muut järjestelmät tukeutuvat siihen. Esimerkiksi GDC 2017 -tapahtumassa pidetyistä 96 ohjelmointipuheesta laskin 31 puhetta grafiikasta, 11 online-puheesta, 10 työkaluista, 4 tekoälystä, 3 fysiikasta, 2 äänestä – mutta vain yksi koski suoraan serialisointia.
Yritä ainakin saada käsitys siitä, kuinka monimutkaisia tarpeitasi tulee olemaan. Jos teet Flappy Birdin kaltaista pientä peliä, jossa on vain muutama assetti, sinun ei luultavasti tarvitse miettiä liikaa sarjallistamista. Voit luultavasti ladata tekstuurit suoraan PNG:stä, ja se käy hyvin. Jos tarvitset kompaktin binääriformaatin, joka on taaksepäin yhteensopiva, mutta et halua kehittää omaa, tutustu kolmannen osapuolen kirjastoihin, kuten Cereal tai Boost.Serialization. En usko, että Google Protocol Buffers on ihanteellinen peliaineistojen sarjallistamiseen, mutta niitä kannattaa silti tutkia.
Pelimoottorin kirjoittaminen – jopa pienen – on iso urakka. Siitä voisi sanoa paljon muutakin, mutta tämän pituiseen postaukseen tämä on rehellisesti sanottuna kaikkein hyödyllisin neuvo, jonka voin antaa: Työskentele iteratiivisesti, vastusta tarvetta yhtenäistää koodia hieman ja tiedä, että sarjallistaminen on iso aihe, jotta voit valita sopivan strategian. Kokemukseni mukaan jokaisesta noista asioista voi tulla kompastuskivi, jos ne jätetään huomiotta.
Rakastan vertailla muistiinpanoja näistä asioista, joten olisin todella kiinnostunut kuulemaan muiden kehittäjien mielipiteitä. Jos olet kirjoittanut moottorin, johtivatko kokemuksesi samoihin johtopäätöksiin? Ja jos et ole kirjoittanut sellaista tai vasta harkitset sitä, olen kiinnostunut myös sinun ajatuksistasi. Mikä on mielestäsi hyvä resurssi, josta kannattaa ottaa oppia? Mitkä osat tuntuvat sinusta vielä salaperäisiltä? Jätä rohkeasti kommentti alla tai ota minuun yhteyttä Twitterissä!