Nedávno jsem psal herní engine v C++. Používám ho k vytvoření malé mobilní hry s názvem Hop Out. Tady je ukázka zachycená z mého iPhonu 6. (Pro zvuk vypněte zvuk!)

Hop Out je hra, kterou chci hrát: Retro arkádová hratelnost s 3D kresleným vzhledem. Cílem je měnit barvu každé podložky, podobně jako ve hře Q*Bert.
Hop Out je stále ve vývoji, ale engine, který ji pohání, začíná být docela zralý, takže jsem si řekl, že se zde podělím o pár tipů ohledně vývoje enginu.
Proč byste chtěli psát herní engine? Existuje mnoho možných důvodů:
- Jste kutil. Rádi vytváříte systémy od základu a vidíte, jak ožívají.
- Chcete se o vývoji her dozvědět více. Strávil jsem v herním průmyslu 14 let a stále se v něm orientuji. Ani jsem si nebyl jistý, jestli bych dokázal napsat engine od nuly, protože se to značně liší od každodenních povinností programátorské práce ve velkém studiu. Chtěl jsem to zjistit.
- Máš rád ovládání. Je uspokojující uspořádat kód přesně podle svých představ a vždy vědět, kde se co nachází.
- Cítíš se inspirován klasickými herními enginy, jako jsou AGI (1984), id Tech 1 (1993), Build (1995), a giganty v oboru, jako jsou Unity a Unreal.
- Myslíš si, že my, herní průmysl, bychom se měli pokusit demystifikovat proces vývoje enginu. Není to tak, že bychom ovládali umění tvorby her. To zdaleka ne! Čím více tento proces prozkoumáme, tím větší máme šanci ho vylepšit.
Herní platformy roku 2017 – mobilní, konzolové a PC – jsou velmi výkonné a v mnoha ohledech si navzájem dost podobné. Vývoj herních enginů už není tolik o boji se slabým a exotickým hardwarem, jako tomu bylo v minulosti. Podle mého názoru jde spíše o boj se složitostí, kterou si sami vytváříte. Je snadné vytvořit monstrum! Proto se rady v tomto příspěvku soustředí na udržování zvládnutelných věcí. Uspořádal jsem je do tří částí:
- Používejte iterativní přístup
- Přemýšlejte dvakrát, než věci příliš sjednotíte
- Uvědomte si, že serializace je velké téma
Tyto rady platí pro jakýkoli druh herního enginu. Nebudu vám říkat, jak napsat shader, co je to octree nebo jak přidat fyziku. To jsou věci, které, předpokládám, už víte, že byste měli vědět – a do značné míry záleží na typu hry, kterou chcete vytvořit. Místo toho jsem záměrně vybral body, které se nezdají být všeobecně známé nebo o kterých se nemluví – jsou to druhy bodů, které považuji za nejzajímavější, když se snažím dané téma demystifikovat.
Používejte iterativní přístup
Moje první rada zní, abyste něco (cokoli!) rychle spustili, a pak iterovali.
Pokud je to možné, začněte s ukázkovou aplikací, která inicializuje zařízení a něco nakreslí na obrazovku. V mém případě jsem si stáhl SDL, otevřel Xcode-iOS/Test/TestiPhoneOS.xcodeproj a pak spustil ukázku testgles2 na iPhonu.

Voilà! Měl jsem krásnou rotující kostku pomocí OpenGL ES 2.0.
Mým dalším krokem bylo stažení 3D modelu, který někdo vytvořil z Maria. Napsal jsem rychlý & špinavý načítací program pro soubor OBJ – formát souboru není tak složitý – a hacknul jsem ukázkovou aplikaci, aby místo kostky vykreslovala Maria. Také jsem integroval SDL_Image, aby mi pomohl načítat textury.

Poté jsem implementoval ovládání dvěma pákami, abych mohl s Mariem pohybovat. (Na začátku jsem uvažoval, že vytvořím střílečku s ovládáním na dvě palice. Ne však s Mariem.“

Dále jsem chtěl prozkoumat skeletální animaci, takže jsem otevřel Blender, vymodeloval chapadlo a rignul ho dvoukostkovou kostrou, která se kývala sem a tam.
V tomto okamžiku jsem opustil formát souborů OBJ a napsal skript Pythonu pro export vlastních souborů JSON z Blenderu. Tyto soubory JSON popisovaly skinovanou síť, kostru a animační data. Tyto soubory jsem načetl do hry pomocí knihovny JSON v jazyce C++.

Když to fungovalo, vrátil jsem se do Blenderu a vytvořil propracovanější postavu. (Byl to první rigged 3D člověk, kterého jsem kdy vytvořil. Byl jsem na něj docela pyšný.“

V průběhu několika dalších měsíců jsem podnikl následující kroky:
- Začal jsem faktorizovat vektorové a maticové funkce do vlastní 3D matematické knihovny.
- Začal jsem nahrazovat
.xcodeprojprojektem CMake. - Zprovoznil jsem engine ve Windows i iOS, protože rád pracuji ve Visual Studiu.
- Začal jsem přesouvat kód do samostatných knihoven „engine“ a „game“. Ty jsem časem rozdělil na ještě granulárnější knihovny.
- Napsal jsem samostatnou aplikaci pro převod mých souborů JSON na binární data, která může hra načítat přímo.
- Ze sestavení pro iOS jsem nakonec odstranil všechny knihovny SDL. (Sestavení pro Windows stále používá SDL.)
Jde o to: Než jsem začal programovat, neplánoval jsem architekturu enginu. Byla to záměrná volba. Místo toho jsem prostě napsal nejjednodušší kód, který implementoval další funkci, a pak jsem se na kód podíval, jaká architektura přirozeně vznikla. Pod pojmem „architektura enginu“ rozumím sadu modulů, které tvoří herní engine, závislosti mezi těmito moduly a rozhraní API pro interakci s jednotlivými moduly.
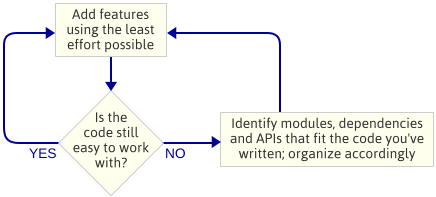
Tento přístup je iterativní, protože se zaměřuje na menší výsledky. Dobře funguje při psaní herního enginu, protože v každém kroku na této cestě máte spuštěný program. Pokud se při zapracovávání kódu do nového modulu něco pokazí, můžete vždy porovnat své změny s kódem, který fungoval dříve. Samozřejmě předpokládám, že používáte nějaký druh kontroly zdrojových kódů.
Možná si myslíte, že se tímto přístupem ztrácí spousta času, protože vždy píšete špatný kód, který je třeba později vyčistit. Ale většina úklidu spočívá v přesouvání kódu z jednoho .cpp souboru do druhého, extrahování deklarací funkcí do .h souborů nebo ve stejně přímočarých změnách. Rozhodování o tom, kam by se věci měly přesunout, je ta těžší část, a to je snazší, když kód již existuje.
Tvrdím, že více času se promarní při opačném přístupu: Příliš usilovná snaha vymyslet architekturu, která bude dělat všechno, co si myslíte, že budete potřebovat dopředu. Dva z mých oblíbených článků o nebezpečí přílišného inženýrství jsou The Vicious Circle of Generalization od Tomasze Dąbrowského a Don’t Let Architecture Astronauts Scare You od Joela Spolskyho.
Neříkám, že byste nikdy neměli řešit problém na papíře, než ho začnete řešit v kódu. Také neříkám, že byste se neměli předem rozhodnout, jaké funkce chcete. Například jsem od začátku věděl, že chci, aby můj engine načítal všechny prostředky ve vlákně na pozadí. Jen jsem se nepokoušel tuto funkci navrhnout nebo implementovat, dokud můj engine skutečně nenačetl nějaké prostředky jako první.
Iterativní přístup mi dal mnohem elegantnější architekturu, než jakou bych kdy mohl vymyslet zíráním na prázdný list papíru. Sestavení mého enginu pro iOS je nyní 100% původní kód včetně vlastní matematické knihovny, šablon kontejnerů, systému reflexe/serializace, vykreslovacího frameworku, fyziky a mixéru zvuku. K napsání každého z těchto modulů jsem měl své důvody, ale možná nebudete považovat za nutné psát všechny tyto věci sami. Existuje spousta skvělých knihoven s otevřeným zdrojovým kódem s povolenou licencí, které by vám místo toho mohly připadat vhodné pro váš engine. GLM, Bullet Physics a hlavičky STB jsou jen několika zajímavými příklady.
Přemýšlejte dvakrát, než začnete věci příliš sjednocovat
Jako programátoři se snažíme vyhnout duplicitě kódu a jsme rádi, když náš kód dodržuje jednotný styl. Myslím si však, že je dobré nenechat tyto instinkty převážit nad každým rozhodnutím.
Resist the DRY Principle Once in a While
Abych uvedl příklad, můj engine obsahuje několik šablonových tříd „chytrých ukazatelů“, v podobném duchu jako std::shared_ptr. Každá z nich pomáhá zabránit únikům paměti tím, že slouží jako obal kolem surového ukazatele.
-
Owned<>je určena pro dynamicky alokované objekty, které mají jediného vlastníka. -
Reference<>používá počítání referencí, aby objekt mohl mít několik vlastníků. -
audio::AppOwned<>používá kód mimo zvukový mixér. Umožňuje herním systémům vlastnit objekty, které používá směšovač zvuku, například právě přehrávaný hlas. -
audio::AudioHandle<>používá systém počítání referencí uvnitř směšovače zvuku.
Může se zdát, že některé z těchto tříd duplikují funkčnost ostatních, čímž porušují zásadu DRY (Don’t Repeat Yourself). Skutečně, na začátku vývoje jsem se snažil v co největší míře znovu použít stávající třídu Reference<>. Zjistil jsem však, že životnost zvukového objektu se řídí zvláštními pravidly: Pokud zvukový hlas dokončil přehrávání ukázky a hra nedrží ukazatel na tento hlas, může být hlas okamžitě zařazen do fronty ke smazání. Pokud hra drží ukazatel, pak by hlasový objekt neměl být odstraněn. A pokud hra drží ukazatel, ale vlastník ukazatele je zničen před ukončením přehrávání hlasu, měl by být hlas zrušen. Místo přidávání složitosti do Reference<> jsem se rozhodl, že bude praktičtější zavést místo toho samostatné šablonové třídy.
V 95 % případů je opětovné použití existujícího kódu správnou cestou. Pokud se však začnete cítit paralyzováni nebo zjistíte, že přidáváte složitost k něčemu, co bylo kdysi jednoduché, zeptejte se sami sebe, zda by něco v kódové základně nemělo být vlastně dvě věci.
Je v pořádku používat různé konvence volání
Jednou věcí, kterou na Javě nemám rád, je, že vás nutí definovat každou funkci uvnitř třídy. To je podle mého názoru nesmysl. Možná díky tomu váš kód vypadá konzistentněji, ale také to podporuje přílišné inženýrství a nehodí se to dobře pro iterativní přístup, který jsem popsal dříve.
V mém enginu C++ některé funkce patří do tříd a některé ne. Například každý nepřítel ve hře je třída a většina jeho chování je implementována uvnitř této třídy, jak byste asi očekávali. Na druhou stranu, obsazování koulí se v mém enginu provádí voláním sphereCast(), funkce ve jmenném prostoru physics. Funkce sphereCast() nepatří do žádné třídy – je pouze součástí modulu physics. Mám sestavovací systém, který spravuje závislosti mezi moduly, což mi udržuje kód dostatečně dobře uspořádaný. Zabalení této funkce do libovolné třídy organizaci kódu nijak smysluplně nezlepší.
Pak je tu dynamické odesílání, což je forma polymorfismu. Často potřebujeme zavolat funkci pro nějaký objekt, aniž bychom znali přesný typ tohoto objektu. Prvním instinktem programátora C++ je definovat abstraktní základní třídu s virtuálními funkcemi a pak tyto funkce přepsat v odvozené třídě. To je správné, ale je to jen jedna z technik. Existují i jiné techniky dynamického odesílání, které nezavádějí tolik kódu navíc nebo přinášejí jiné výhody:
- C++11 zavedl
std::function, což je pohodlný způsob ukládání zpětných volání funkcí. Je také možné napsat vlastní verzistd::function, do které je méně bolestivé vstupovat v debuggeru. - Mnoho zpětných funkcí lze implementovat pomocí dvojice ukazatelů: Ukazatel na funkci a neprůhledný argument. Vyžaduje to jen explicitní obsazení uvnitř funkce zpětného volání. S tím se často setkáte v knihovnách v čistém jazyce C.
- Někdy je základní typ skutečně znám již při kompilaci a volání funkce můžete svázat bez další režie za běhu. Turf, knihovna, kterou používám ve svém herním enginu, na tuto techniku hodně spoléhá. Viz například
turf::Mutex. Je to jentypedefnad třídou specifickou pro danou platformu. - Někdy je nejjednodušším přístupem sestavit a udržovat tabulku nezpracovaných ukazatelů na funkce sami. Tento přístup jsem použil ve svém audio mixéru a serializačním systému. Interpret jazyka Python tuto techniku také hojně využívá, jak je uvedeno níže.
- Ukazatele na funkce můžete dokonce ukládat do hashovací tabulky, přičemž jako klíče použijete názvy funkcí. Tuto techniku používám k odesílání vstupních událostí, například událostí multitouch. Je to součást strategie zaznamenávání herních vstupů a jejich přehrávání pomocí systému přehrávání.
Dynamické odesílání je velké téma. Jen jsem poškrábal povrch, abych ukázal, že existuje mnoho způsobů, jak toho dosáhnout. Čím více píšete rozšiřitelný nízkoúrovňový kód – což je v herním enginu běžné – tím více budete zkoumat alternativy. Pokud nejste na tento druh programování zvyklí, interpret jazyka Python, který je napsán v jazyce C, je vynikajícím zdrojem, ze kterého se můžete učit. Implementuje výkonný objektový model: Každý PyObject ukazuje na PyTypeObject a každý PyTypeObject obsahuje tabulku ukazatelů na funkce pro dynamické odesílání. Dokument Definování nových typů je dobrým výchozím bodem, pokud se chcete rovnou pustit do práce.
Uvědomte si, že serializace je velké téma
Serializace je akt převodu runtime objektů na a z posloupnosti bajtů. Jinými slovy, ukládání a načítání dat.
Pro mnoho, ne-li většinu herních enginů je herní obsah vytvářen v různých upravitelných formátech, jako jsou .png, .json, .blend nebo proprietární formáty, a poté nakonec převeden do herních formátů specifických pro danou platformu, které může engine rychle načíst. Poslední aplikace v tomto potrubí se často označuje jako „vařič“. Cooker může být integrován do jiného nástroje nebo dokonce distribuován na několik strojů. Obvykle jsou cooker a řada nástrojů vyvíjeny a udržovány společně se samotným herním enginem.
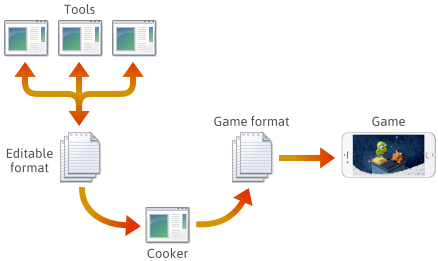
Při nastavení takovéto pipeline je volba formátu souboru v každé fázi na vás. Můžete definovat některé vlastní formáty souborů a tyto formáty se mohou vyvíjet s tím, jak budete přidávat funkce enginu. Při jejich vývoji možná zjistíte, že je nutné zachovat kompatibilitu některých programů s dříve uloženými soubory. Bez ohledu na formát je nakonec budete muset serializovat v jazyce C++.
Existuje nespočet způsobů, jak serializaci v jazyce C++ implementovat. Jedním z poměrně zřejmých způsobů je přidání funkcí load a save do tříd jazyka C++, které chcete serializovat. Zpětné kompatibility můžete dosáhnout uložením čísla verze v hlavičce souboru a následným předáním tohoto čísla do každé funkce load. To funguje, i když se kód může stát těžkopádným na údržbu.
void load(InStream& in, u32 fileVersion) { // Load expected member variables in >> m_position; in >> m_direction; // Load a newer variable only if the file version being loaded is 2 or greater if (fileVersion >= 2) { in >> m_velocity; } }
Serializační kód je možné psát pružněji a méně náchylně k chybám využitím reflexe – konkrétně vytvořením runtime dat, která popisují rozložení vašich typů C++. Pro rychlou představu, jak může reflexe pomoci se serializací, se podívejte, jak to dělá Blender, open source projekt.
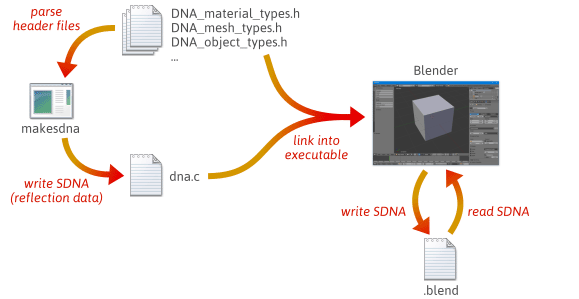
Při sestavování Blenderu ze zdrojového kódu dochází k mnoha krokům. Nejprve se zkompiluje a spustí vlastní nástroj s názvem makesdna. Tento nástroj analyzuje sadu hlavičkových souborů C ve stromu zdrojových kódů programu Blender a poté vypíše kompaktní přehled všech typů C, které jsou v nich definovány, ve vlastním formátu známém jako SDNA. Tato data SDNA slouží jako odrazová data. SDNA je pak propojeno se samotným programem Blender a uloženo s každým .blend souborem, který program Blender zapíše. Od tohoto okamžiku, kdykoli program Blender načte soubor .blend, porovná SDNA souboru .blend s SDNA nalinkovaným do aktuální verze za běhu a použije generický serializační kód pro zpracování případných rozdílů. Tato strategie poskytuje programu Blender působivou míru zpětné i dopředné kompatibility. Soubory verze 1.0 můžete stále načítat v nejnovější verzi programu Blender a nové .blend soubory lze načítat i ve starších verzích.
Stejně jako Blender i mnoho herních enginů – a s nimi spojených nástrojů – generuje a používá svá vlastní reflexní data. Existuje mnoho způsobů, jak to udělat: Můžete analyzovat vlastní zdrojový kód C/C++ a získat z něj typové informace, jako to dělá Blender. Můžete vytvořit samostatný jazyk pro popis dat a napsat nástroj pro generování definic typů C++ a reflexních dat z tohoto jazyka. Ke generování reflexních dat za běhu můžete použít makra preprocesoru a šablony jazyka C++. A jakmile máte reflexní data k dispozici, existuje nespočet způsobů, jak nad nimi napsat generický serializér.
Je jasné, že vynechávám spoustu detailů. V tomto příspěvku chci pouze ukázat, že existuje mnoho různých způsobů serializace dat, z nichž některé jsou velmi složité. Programátoři prostě o serializaci nediskutují tolik jako o jiných systémech motorů, přestože většina ostatních systémů na ni spoléhá. Například z 96 přednášek o programování na GDC 2017 jsem napočítal 31 přednášek o grafice, 11 o online, 10 o nástrojích, 4 o umělé inteligenci, 3 o fyzice, 2 o zvuku – ale jen jedna se dotýkala přímo serializace.
Zkuste si minimálně udělat představu, jak složité budou vaše potřeby. Pokud děláte malou hru, jako je Flappy Bird, jen s několika málo prostředky, pravděpodobně nemusíte o serializaci příliš přemýšlet. Pravděpodobně můžete načítat textury přímo z PNG a bude to v pořádku. Pokud potřebujete kompaktní binární formát se zpětnou kompatibilitou, ale nechcete vyvíjet vlastní, podívejte se na knihovny třetích stran, jako je Cereal nebo Boost.Serialization. Nemyslím si, že Google Protocol Buffers jsou pro serializaci herních prostředků ideální, ale přesto stojí za prostudování.
Napsat herní engine – i malý – je velký úkol. Mohl bych k tomu říct mnohem víc, ale na tak dlouhý příspěvek je to upřímně řečeno ta nejužitečnější rada, která mě napadá: Pracujte iterativně, odolejte nutkání trochu unifikovat kód a vězte, že serializace je velké téma, abyste mohli zvolit vhodnou strategii. Podle mých zkušeností se každá z těchto věcí může stát kamenem úrazu, pokud se ignoruje.
Rad si o těchto věcech porovnávám poznámky, takže by mě opravdu zajímalo, co o tom řeknou ostatní vývojáři. Pokud jste napsali engine, vedly vás vaše zkušenosti k některému ze stejných závěrů? A pokud jste žádný nenapsali nebo o tom teprve uvažujete, také mě zajímají vaše názory. Co považujete za dobrý zdroj informací, ze kterého se můžete poučit? Které části vám stále připadají záhadné? Neváhejte a zanechte komentář níže nebo mě kontaktujte na Twitteru!