På senare tid har jag skrivit en spelmotor i C++. Jag använder den för att göra ett litet mobilspel som heter Hop Out. Här är ett klipp som tagits från min iPhone 6. (Ta bort ljudet!)

Hop Out är den typ av spel som jag vill spela: Retro arkadspel med ett 3D-utseende som ser ut som en tecknad film. Målet är att ändra färgen på varje pad, som i Q*Bert.
Hop Out är fortfarande under utveckling, men motorn som driver det börjar bli ganska mogen, så jag tänkte att jag skulle dela med mig av några tips om motorutveckling här.
Varför vill du skriva en spelmotor? Det finns många möjliga anledningar:
- Du är en pysslare. Du älskar att bygga system från grunden och se dem komma till liv.
- Du vill lära dig mer om spelutveckling. Jag har tillbringat 14 år i spelbranschen och jag håller fortfarande på att förstå den. Jag var inte ens säker på att jag skulle kunna skriva en motor från grunden, eftersom det är enormt annorlunda än det dagliga ansvaret för ett programmeringsjobb på en stor studio. Jag ville ta reda på det.
- Du gillar kontroll. Det är tillfredsställande att organisera koden precis som man vill och veta var allting finns hela tiden.
- Du känner dig inspirerad av klassiska spelmotorer som AGI (1984), id Tech 1 (1993), Build (1995) och branschjättar som Unity och Unreal.
- Du anser att vi i spelbranschen borde försöka avmystifiera motorutvecklingsprocessen. Det är inte så att vi behärskar konsten att göra spel. Långt ifrån! Ju mer vi undersöker denna process, desto större är våra chanser att förbättra den.
Spelplattformarna 2017 – mobil, konsol och PC – är mycket kraftfulla och på många sätt ganska lika varandra. Utveckling av spelmotorer handlar inte så mycket om att kämpa med svag och exotisk hårdvara som tidigare. Enligt min mening handlar det snarare om att kämpa med komplexitet som man själv har skapat. Det är lätt att skapa ett monster! Det är därför som råden i det här inlägget är inriktade på att hålla saker och ting hanterbara. Jag har organiserat det i tre avsnitt:
- Använd ett iterativt tillvägagångssätt
- Tänk efter två gånger innan du förenhetligar saker och ting för mycket
- Var medveten om att serialisering är ett stort ämne
Det här rådet gäller för alla typer av spelmotorer. Jag tänker inte berätta hur man skriver en shader, vad en octree är eller hur man lägger till fysik. Det är sådana saker som jag antar att du redan vet att du bör veta – och det beror till stor del på vilken typ av spel du vill göra. Istället har jag medvetet valt punkter som inte verkar vara allmänt erkända eller omtalade – det är den typen av punkter som jag tycker är mest intressanta när jag försöker avmystifiera ett ämne.
Använd ett iterativt tillvägagångssätt
Mitt första råd är att få något (vad som helst!) att fungera snabbt, och sedan iterera.
Om det är möjligt bör du börja med en exempelapplikation som initialiserar enheten och ritar upp något på skärmen. I mitt fall laddade jag ner SDL, öppnade Xcode-iOS/Test/TestiPhoneOS.xcodeproj och körde sedan testgles2-exemplet på min iPhone.

Voilà! Jag hade en härlig snurrande kub med OpenGL ES 2.0.
Mitt nästa steg var att ladda ner en 3D-modell som någon gjort av Mario. Jag skrev en snabb & smutsig OBJ-filsladdare – filformatet är inte så komplicerat – och hackade exempelprogrammet för att rendera Mario i stället för en kub. Jag integrerade också SDL_Image för att hjälpa till att ladda texturer.

Därefter implementerade jag kontroller med dubbla styrspakar för att flytta Mario. (I början funderade jag på att göra en dual-stick shooter. Men inte med Mario.)

Nästan ville jag utforska skelettanimation, så jag öppnade Blender, modellerade en tentakel och riggade den med ett skelett med två ben som vickade fram och tillbaka.
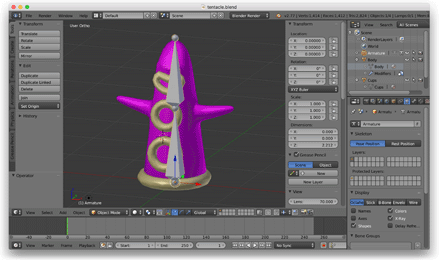
När jag kom till den här punkten övergav jag OBJ-filformatet och skrev ett Pythonskript för att exportera anpassade JSON-filer från Blender. Dessa JSON-filer beskrev det skinnade nätet, skelettet och animationsdata. Jag laddade in dessa filer i spelet med hjälp av ett C++ JSON-bibliotek.

När det fungerade gick jag tillbaka till Blender och gjorde mer genomarbetade karaktärer. (Detta var den första riggade 3D-människa jag någonsin skapat. Jag var ganska stolt över honom.)

Under de kommande månaderna tog jag följande steg:
- Först började jag faktorisera vektor- och matrisfunktioner i mitt eget 3D-matematiska bibliotek.
- Ersatte
.xcodeprojmed ett CMake-projekt. - Fick igång motorn på både Windows och iOS, eftersom jag gillar att arbeta i Visual Studio.
- Begick att flytta kod till separata bibliotek för ”motor” och ”spel”. Med tiden delade jag upp dessa i ännu mer granulära bibliotek.
- Skrev ett separat program för att konvertera mina JSON-filer till binära data som spelet kan läsa in direkt.
- Till slut tog jag bort alla SDL-bibliotek från iOS-bygget. (Windows-bygget använder fortfarande SDL.)
Punkten är: Jag planerade inte motorarkitekturen innan jag började programmera. Detta var ett medvetet val. Istället skrev jag bara den enklaste koden som implementerade nästa funktion, sedan tittade jag på koden för att se vilken typ av arkitektur som uppstod naturligt. Med ”motorarkitektur” menar jag den uppsättning moduler som utgör spelmotorn, beroendena mellan dessa moduler och API:et för att interagera med varje modul.
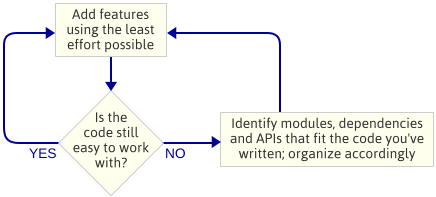
Detta är ett iterativt tillvägagångssätt eftersom det fokuserar på mindre leveranser. Det fungerar bra när man skriver en spelmotor eftersom man vid varje steg på vägen har ett fungerande program. Om något går fel när du faktoriserar kod i en ny modul kan du alltid jämföra dina ändringar med den kod som fungerade tidigare. Självklart förutsätter jag att du använder någon form av källkontroll.
Du kanske tror att mycket tid går till spillo med det här tillvägagångssättet, eftersom du alltid skriver dålig kod som måste rensas upp senare. Men det mesta av rensningen handlar om att flytta kod från en .cpp fil till en annan, extrahera funktionsdeklarationer till .h filer, eller lika enkla ändringar. Att bestämma var saker och ting ska ta vägen är den svåra delen, och det är lättare att göra när koden redan finns.
Jag skulle vilja påstå att mer tid går till spillo med det motsatta tillvägagångssättet: Man försöker för hårt att komma fram till en arkitektur som gör allt man tror att man kommer att behöva i förväg. Två av mina favoritartiklar om farorna med överdriven ingenjörskonst är The Vicious Circle of Generalization av Tomasz Dąbrowski och Don’t Let Architecture Astronauts Scare You av Joel Spolsky.
Jag säger inte att du aldrig ska lösa ett problem på papper innan du tar itu med det i kod. Jag säger inte heller att du inte ska bestämma vilka funktioner du vill ha i förväg. Jag visste till exempel redan från början att jag ville att min motor skulle ladda alla tillgångar i en bakgrundstråd. Jag försökte bara inte utforma eller implementera den funktionen förrän min motor faktiskt laddade några tillgångar först.
Det iterativa tillvägagångssättet har gett mig en mycket elegantare arkitektur än vad jag någonsin hade kunnat drömma om genom att stirra på ett tomt pappersark. iOS-bygget av min motor består nu till 100 % av originalkod, inklusive ett anpassat matematiskt bibliotek, containermallar, reflektions-/serialiseringssystem, renderingsramverk, fysik och ljudmixer. Jag hade skäl att skriva var och en av dessa moduler, men du kanske inte tycker att det är nödvändigt att skriva alla dessa saker själv. Det finns massor av bra, tillåtande licensierade open source-bibliotek som du kanske finner lämpliga för din motor istället. GLM, Bullet Physics och STB-headers är bara några intressanta exempel.
Tänk två gånger innan du förenhetligar saker för mycket
Som programmerare försöker vi undvika koddubblering, och vi gillar när vår kod följer en enhetlig stil. Jag tror dock att det är bra att inte låta dessa instinkter styra över varje beslut.
Resist the DRY Principle Once in a While
För att ge dig ett exempel innehåller min motor flera ”smart pointer”-mallklasser, som liknar i andan std::shared_ptr. Var och en hjälper till att förhindra minnesläckage genom att fungera som en wrapper runt en råpekare.
-
Owned<>är för dynamiskt allokerade objekt som har en enda ägare. -
Reference<>använder referensräkning för att ett objekt ska kunna ha flera ägare. -
audio::AppOwned<>används av kod utanför ljudmixern. Den gör det möjligt för spelsystem att äga objekt som ljudmixern använder, t.ex. en röst som spelas upp för tillfället. -
audio::AudioHandle<>använder ett referensräkningssystem internt i ljudmixern.
Det kan se ut som om vissa av dessa klasser duplicerar funktionaliteten hos de andra, vilket är ett brott mot DRY-principen (Don’t Repeat Yourself). Tidigare under utvecklingen försökte jag faktiskt återanvända den befintliga klassen Reference<> så mycket som möjligt. Jag upptäckte dock att livstiden för ett ljudobjekt styrs av särskilda regler: Om en ljudröst har spelat upp ett prov och spelet inte har någon pekare på den rösten, kan rösten ställas i kö för radering omedelbart. Om spelet har en pekare ska röstobjektet inte raderas. Och om spelet har en pekare, men pekarens ägare förstörs innan rösten har avslutats, bör rösten avbrytas. I stället för att öka komplexiteten i Reference<> bestämde jag mig för att det var mer praktiskt att införa separata mallklasser i stället.
95% av tiden är återanvändning av befintlig kod rätt väg att gå. Men om du börjar känna dig förlamad, eller om du upptäcker att du lägger till komplexitet till något som en gång var enkelt, fråga dig själv om något i kodbasen faktiskt borde vara två saker.
Det är okej att använda olika anropskonventioner
En sak som jag ogillar med Java är att det tvingar dig att definiera varje funktion inuti en klass. Det är nonsens enligt min mening. Det kan få din kod att se mer konsekvent ut, men det uppmuntrar också till överkonstruktion och lämpar sig inte bra för det iterativa tillvägagångssättet som jag beskrev tidigare.
I min C++-motor hör vissa funktioner hemma i klasser och andra inte. Till exempel är varje fiende i spelet en klass, och det mesta av fiendens beteende implementeras i den klassen, vilket du förmodligen förväntar dig. Å andra sidan utförs sphere casts i min motor genom att anropa sphereCast(), en funktion i namnområdet physics. sphereCast() tillhör inte någon klass – den är bara en del av physics-modulen. Jag har ett byggsystem som hanterar beroenden mellan moduler, vilket håller koden organiserad tillräckligt bra för mig. Att linda in den här funktionen i en godtycklig klass förbättrar inte kodorganisationen på något meningsfullt sätt.
Därefter finns dynamisk dispatch, som är en form av polymorfism. Vi behöver ofta anropa en funktion för ett objekt utan att veta den exakta typen av detta objekt. En C++-programmerares första instinkt är att definiera en abstrakt basklass med virtuella funktioner och sedan åsidosätta dessa funktioner i en härledd klass. Det är giltigt, men det är bara en teknik. Det finns andra dynamiska avsändningstekniker som inte introducerar lika mycket extra kod, eller som ger andra fördelar:
- C++11 introducerade
std::function, som är ett bekvämt sätt att lagra callback-funktioner. Det är också möjligt att skriva en egen version avstd::functionsom är mindre smärtsam att kliva in i i felsökaren. - Många callback-funktioner kan implementeras med ett par pekare: En funktionspekare och ett ogenomskinligt argument. Det kräver bara en explicit cast inne i callback-funktionen. Du ser detta ofta i rena C-bibliotek.
- I vissa fall är den underliggande typen faktiskt känd vid kompileringstid och du kan binda funktionsanropet utan ytterligare körtidsöverskott. Turf, ett bibliotek som jag använder i min spelmotor, förlitar sig ofta på denna teknik. Se till exempel
turf::Mutex. Det är bara entypedeföver en plattformsspecifik klass. - Ibland är den enklaste metoden att själv bygga och underhålla en tabell med råa funktionspekare. Jag använde detta tillvägagångssätt i min ljudmixer och mitt serialiseringssystem. Python-tolken använder sig också flitigt av den här tekniken, vilket nämns nedan.
- Du kan till och med lagra funktionspekare i en hashtabell och använda funktionsnamnen som nycklar. Jag använder den här tekniken för att skicka inmatningshändelser, t.ex. multitouchhändelser. Det är en del av en strategi för att registrera spelinmatningar och spela upp dem med ett återspelningssystem.
Dynamisk avsändning är ett stort ämne. Jag skrapar bara på ytan för att visa att det finns många sätt att uppnå det. Ju mer du skriver utbyggbar kod på låg nivå – vilket är vanligt i en spelmotor – desto mer kommer du att upptäcka att du utforskar alternativ. Om du inte är van vid denna typ av programmering är Python-tolken, som är skriven i C, en utmärkt resurs att lära sig från. Den implementerar en kraftfull objektmodell: Varje PyObject pekar på en PyTypeObject, och varje PyTypeObject innehåller en tabell med funktionspekare för dynamisk avsändning. Dokumentet Defining New Types är en bra utgångspunkt om du vill hoppa direkt in i det.
Var medveten om att serialisering är ett stort ämne
Serialisering är en handling som omvandlar körtidsobjekt till och från en sekvens av bytes. Med andra ord, att spara och ladda data.
För många, om inte de flesta spelmotorer, skapas spelinnehållet i olika redigerbara format som .png, .json, .blend eller proprietära format, som sedan så småningom konverteras till plattformsspecifika spelformat som motorn kan ladda snabbt. Det sista programmet i denna pipeline kallas ofta för en ”kokare”. Kokaren kan integreras i ett annat verktyg eller till och med distribueras över flera maskiner. Vanligtvis utvecklas och underhålls cookern och ett antal verktyg tillsammans med själva spelmotorn.
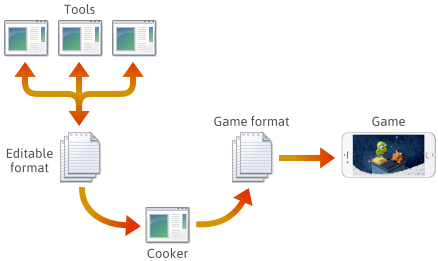
När du sätter upp en sådan pipeline är valet av filformat i varje steg upp till dig. Du kanske definierar några egna filformat, och dessa format kan utvecklas i takt med att du lägger till motorfunktioner. När de utvecklas kan du finna det nödvändigt att hålla vissa program kompatibla med tidigare sparade filer. Oavsett vilket format som används kommer du i slutändan att behöva serialisera det i C++.
Det finns otaliga sätt att implementera serialisering i C++. Ett ganska uppenbart sätt är att lägga till load och save-funktioner till de C++-klasser som du vill serialisera. Du kan uppnå bakåtkompatibilitet genom att lagra ett versionsnummer i filhuvudet och sedan skicka detta nummer till varje load-funktion. Detta fungerar, även om koden kan bli besvärlig att underhålla.
void load(InStream& in, u32 fileVersion) { // Load expected member variables in >> m_position; in >> m_direction; // Load a newer variable only if the file version being loaded is 2 or greater if (fileVersion >= 2) { in >> m_velocity; } }
Det är möjligt att skriva mer flexibel och mindre felbenägen serialiseringskod genom att dra nytta av reflection – närmare bestämt genom att skapa runtime-data som beskriver layouten för dina C++-typer. För att få en snabb uppfattning om hur reflection kan hjälpa till med serialisering kan du ta en titt på hur Blender, ett projekt med öppen källkod, gör det.
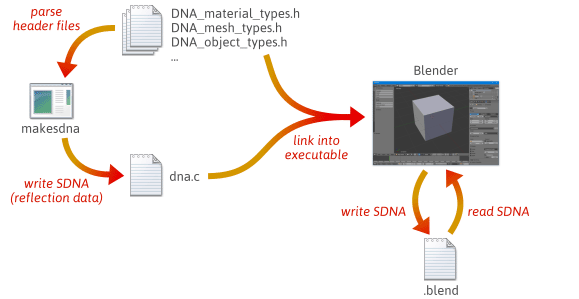
När du bygger Blender från källkod sker många steg. Först kompileras och körs ett anpassat verktyg som heter makesdna. Det här verktyget analyserar en uppsättning C header-filer i Blenders källkodsträd och ger sedan ut en kompakt sammanfattning av alla C-typer som definieras i dem, i ett anpassat format som kallas SDNA. Dessa SDNA-data tjänar som reflektionsdata. SDNA länkas sedan in i Blender själv och sparas med varje .blend-fil som Blender skriver. Från och med då jämför Blender, närhelst Blender laddar en .blend-fil, .blend-filens SDNA med den SDNA som är länkad till den aktuella versionen vid körning, och använder generisk serialiseringskod för att hantera eventuella skillnader. Denna strategi ger Blender en imponerande grad av bakåt- och framåtkompatibilitet. Du kan fortfarande ladda 1.0-filer i den senaste versionen av Blender, och nya .blend-filer kan laddas i äldre versioner.
Likt Blender genererar och använder många spelmotorer – och deras tillhörande verktyg – sina egna reflektionsdata. Det finns många sätt att göra det på: Du kan analysera din egen C/C++-källkod för att extrahera typinformation, som Blender gör. Du kan skapa ett separat databeskrivningsspråk och skriva ett verktyg för att generera C++-typdefinitioner och reflektionsdata från detta språk. Du kan använda preprocessormakron och C++-mallar för att generera reflektionsdata vid körning. Och när du väl har reflektionsdata tillgängliga finns det otaliga sätt att skriva en generisk serialiserare ovanpå den.
Det är uppenbart att jag utelämnar en hel del detaljer. I det här inlägget vill jag bara visa att det finns många olika sätt att serialisera data, varav vissa är mycket komplexa. Programmerare diskuterar helt enkelt inte serialisering lika mycket som andra motorsystem, trots att de flesta andra system är beroende av det. Till exempel, av de 96 programmeringssamtal som hölls på GDC 2017 räknade jag 31 samtal om grafik, 11 om online, 10 om verktyg, 4 om AI, 3 om fysik, 2 om ljud – men bara ett som berörde serialisering direkt.
Att åtminstone försöka ha en uppfattning om hur komplexa dina behov kommer att vara. Om du gör ett litet spel som Flappy Bird, med bara några få tillgångar, behöver du förmodligen inte tänka så mycket på serialisering. Du kan förmodligen ladda texturer direkt från PNG och det kommer att gå bra. Om du behöver ett kompakt binärt format med bakåtkompatibilitet, men inte vill utveckla ett eget, kan du ta en titt på tredjepartsbibliotek som Cereal eller Boost.Serialization. Jag tror inte att Google Protocol Buffers är idealiska för serialisering av speltillgångar, men de är värda att studera ändå.
Att skriva en spelmotor – även en liten sådan – är ett stort åtagande. Det finns mycket mer jag skulle kunna säga om det, men för ett inlägg av den här längden är det ärligt talat det mest hjälpsamma råd jag kan tänka mig att ge: Arbeta iterativt, motstå suget att förenhetliga koden lite grann och vet att serialisering är ett stort ämne så att du kan välja en lämplig strategi. Enligt min erfarenhet kan var och en av dessa saker bli en stötesten om de ignoreras.
Jag älskar att jämföra anteckningar om dessa saker, så jag skulle vara väldigt intresserad av att höra från andra utvecklare. Om du har skrivit en motor, har din erfarenhet lett dig till några av samma slutsatser? Och om du inte har skrivit någon, eller bara funderar på det, är jag också intresserad av dina tankar. Vad anser du vara en bra resurs att lära sig av? Vilka delar verkar fortfarande mystiska för dig? Lämna gärna en kommentar nedan eller kontakta mig på Twitter!