În ultima vreme am scris un motor de joc în C++. Îl folosesc pentru a face un mic joc mobil numit Hop Out. Iată un clip capturat de pe iPhone 6 al meu. (Unmute pentru sunet!)

Hop Out este genul de joc pe care vreau să îl joc: Un gameplay retro arcade cu un aspect de desen animat 3D. Scopul este de a schimba culoarea fiecărui pad, ca în Q*Bert.
Hop Out este încă în dezvoltare, dar motorul care îl alimentează începe să devină destul de matur, așa că m-am gândit să împărtășesc aici câteva sfaturi despre dezvoltarea motorului.
De ce ai vrea să scrii un motor de joc? Există multe motive posibile:
- Ești un tinichigiu. Vă place să construiți sisteme de la zero și să le vedeți cum prind viață.
- Vreți să învățați mai multe despre dezvoltarea de jocuri. Am petrecut 14 ani în industria jocurilor și încă mă descurc. Nici măcar nu eram sigur că aș putea scrie un motor de la zero, deoarece este foarte diferit de responsabilitățile zilnice ale unui loc de muncă de programare la un studio mare. Am vrut să aflu.
- Îți place controlul. Este satisfăcător să organizezi codul exact așa cum îți dorești, știind unde se află totul în orice moment.
- Te simți inspirat de motoarele de jocuri clasice, cum ar fi AGI (1984), id Tech 1 (1993), Build (1995) și de giganții industriei, cum ar fi Unity și Unreal.
- Crezi că noi, industria jocurilor, ar trebui să încercăm să demistificăm procesul de dezvoltare a motoarelor. Nu e ca și cum am fi stăpânit arta de a face jocuri. Departe de asta! Cu cât examinăm mai mult acest proces, cu atât mai mari sunt șansele noastre de a-l îmbunătăți.
Platformele de jocuri din 2017 – mobil, consolă și PC – sunt foarte puternice și, în multe privințe, destul de asemănătoare între ele. Dezvoltarea motoarelor de jocuri nu mai înseamnă atât de mult să te lupți cu hardware slab și exotic, așa cum era în trecut. În opinia mea, este mai mult despre a te lupta cu complexitatea pe care ți-o creezi singur. Este ușor să creezi un monstru! De aceea, sfaturile din această postare se axează pe menținerea lucrurilor gestionabile. L-am organizat în trei secțiuni:
- Utilizați o abordare iterativă
- Gândiți-vă de două ori înainte de a unifica prea mult lucrurile
- Fiți conștienți de faptul că serializarea este un subiect mare
Acest sfat este valabil pentru orice tip de motor de joc. Nu am de gând să vă spun cum să scrieți un shader, ce este un octree sau cum să adăugați fizică. Acestea sunt genul de lucruri pe care, presupun, știți deja că ar trebui să le știți – și depinde în mare măsură de tipul de joc pe care doriți să îl faceți. În schimb, am ales în mod deliberat puncte care nu par a fi recunoscute sau despre care nu se vorbește pe scară largă – acestea sunt tipurile de puncte pe care le consider cele mai interesante atunci când încerc să demistific un subiect.
Utilizați o abordare iterativă
Primul meu sfat este să faceți ceva (orice!) să ruleze rapid, apoi să iterați.
Dacă este posibil, începeți cu o aplicație de probă care inițializează dispozitivul și desenează ceva pe ecran. În cazul meu, am descărcat SDL, am deschis Xcode-iOS/Test/TestiPhoneOS.xcodeproj, apoi am rulat exemplul testgles2 pe iPhone-ul meu.

Voilà! Aveam un cub minunat care se învârtea folosind OpenGL ES 2.0.
Următorul meu pas a fost să descarc un model 3D făcut de cineva cu Mario. Am scris un încărcător rapid & murdar de fișiere OBJ – formatul fișierului nu este atât de complicat – și am modificat aplicația de probă pentru a-l reda pe Mario în loc de un cub. Am integrat, de asemenea, SDL_Image pentru a ajuta la încărcarea texturilor.

Apoi am implementat comenzi dual-stick pentru a-l deplasa pe Mario. (La început, mă gândeam să fac un shooter dual-stick. Nu cu Mario, totuși.)

În continuare, am vrut să explorez animația scheletului, așa că am deschis Blender, am modelat un tentacul și l-am echipat cu un schelet cu două oase care se mișca înainte și înapoi.
În acest moment, am renunțat la formatul de fișiere OBJ și am scris un script Python pentru a exporta fișiere JSON personalizate din Blender. Aceste fișiere JSON descriau plasa de piele, scheletul și datele de animație. Am încărcat aceste fișiere în joc cu ajutorul unei biblioteci JSON C++.

După ce a funcționat, m-am întors în Blender și am creat un personaj mai elaborat. (Acesta a fost primul om 3D rigged pe care l-am creat vreodată. Am fost destul de mândru de el.)

În următoarele câteva luni, am făcut următorii pași:
- Am început să factorizez funcții vectoriale și matriciale în propria mea bibliotecă matematică 3D.
- Am înlocuit
.xcodeprojcu un proiect CMake. - Am făcut ca motorul să funcționeze atât pe Windows, cât și pe iOS, pentru că îmi place să lucrez în Visual Studio.
- Am început să mut codul în biblioteci „motor” și „joc” separate. În timp, le-am împărțit pe acestea în biblioteci și mai granulare.
- Am scris o aplicație separată pentru a-mi converti fișierele JSON în date binare pe care jocul le poate încărca direct.
- Am eliminat în cele din urmă toate bibliotecile SDL din construcția iOS. (Construcția pentru Windows încă mai folosește SDL.)
Subiectul este: Nu am planificat arhitectura motorului înainte de a începe să programez. Aceasta a fost o alegere deliberată. În schimb, am scris cel mai simplu cod care să implementeze următoarea caracteristică, apoi mă uitam la cod pentru a vedea ce fel de arhitectură a apărut în mod natural. Prin „arhitectura motorului”, mă refer la setul de module care alcătuiesc motorul de joc, dependențele dintre aceste module și API-ul pentru a interacționa cu fiecare modul.
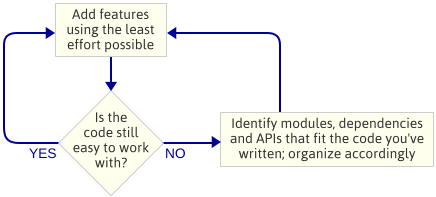
Aceasta este o abordare iterativă, deoarece se concentrează pe livrabile mai mici. Funcționează bine atunci când se scrie un motor de joc deoarece, la fiecare pas pe parcurs, aveți un program care rulează. Dacă ceva nu merge bine atunci când factorizați codul într-un nou modul, puteți oricând să vă comparați modificările cu codul care a funcționat anterior. Evident, presupun că folosiți un fel de control al sursei.
Ați putea crede că se pierde mult timp în această abordare, deoarece scrieți mereu cod prost care trebuie curățat ulterior. Dar cea mai mare parte a curățării implică mutarea codului dintr-un fișier .cpp în altul, extragerea declarațiilor de funcții în fișiere .h, sau modificări la fel de simple. A decide unde ar trebui să se ducă lucrurile este partea dificilă, iar acest lucru este mai ușor de făcut atunci când codul există deja.
Am spune că se pierde mai mult timp în abordarea opusă: Încercarea de a găsi prea mult timp o arhitectură care să facă tot ceea ce credeți că veți avea nevoie din timp. Două dintre articolele mele preferate despre pericolele ingineriei excesive sunt The Vicious Circle of Generalization (Cercul vicios al generalizării) de Tomasz Dąbrowski și Don’t Let Architecture Astronauts Scare You (Nu lăsați astronauții de arhitectură să vă sperie) de Joel Spolsky.
Nu spun că nu ar trebui să rezolvați niciodată o problemă pe hârtie înainte de a o aborda în cod. De asemenea, nu spun că nu ar trebui să decideți în prealabil ce caracteristici doriți. De exemplu, am știut de la început că vreau ca motorul meu să încarce toate activele într-un fir de fundal. Pur și simplu nu am încercat să proiectez sau să implementez această caracteristică până când motorul meu nu a încărcat efectiv mai întâi câteva active.
Abordarea iterativă mi-a oferit o arhitectură mult mai elegantă decât aș fi putut visa vreodată uitându-mă la o foaie albă de hârtie. Construcția iOS a motorului meu este acum 100% cod original, inclusiv o bibliotecă matematică personalizată, șabloane de containere, sistem de reflexie/serializare, cadru de redare, fizică și mixer audio. Am avut motive pentru a scrie fiecare dintre aceste module, dar s-ar putea să nu vi se pară necesar să scrieți singuri toate aceste lucruri. Există o mulțime de biblioteci open source grozave, cu licență permisivă, pe care le-ați putea găsi potrivite pentru motorul dvs. în schimb. GLM, Bullet Physics și anteturile STB sunt doar câteva exemple interesante.
Gândiți-vă de două ori înainte de a unifica prea mult lucrurile
Ca programatori, încercăm să evităm duplicarea codului și ne place când codul nostru urmează un stil uniform. Cu toate acestea, cred că este bine să nu lăsăm aceste instincte să prevaleze asupra fiecărei decizii.
Rezistați la principiul DRY din când în când
Pentru a vă da un exemplu, motorul meu conține mai multe clase de șabloane „pointer inteligent”, similare în spirit cu std::shared_ptr. Fiecare dintre ele ajută la prevenirea scurgerilor de memorie, servind ca un înveliș în jurul unui pointer brut.
-
Owned<>este pentru obiectele alocate dinamic care au un singur proprietar. -
Reference<>utilizează numărarea referințelor pentru a permite ca un obiect să aibă mai mulți proprietari. -
audio::AppOwned<>este utilizat de codul din afara mixerului audio. Permite sistemelor de joc să dețină obiecte pe care mixerul audio le folosește, cum ar fi o voce care este în curs de redare. -
audio::AudioHandle<>utilizează un sistem de numărare a referințelor intern al mixerului audio.
Se poate părea că unele dintre aceste clase dublează funcționalitatea celorlalte, încălcând principiul DRY (Don’t Repeat Yourself). Într-adevăr, la începutul dezvoltării, am încercat să reutilizez cât mai mult posibil clasa existentă Reference<>. Cu toate acestea, am constatat că durata de viață a unui obiect audio este guvernată de reguli speciale: Dacă o voce audio a terminat de redat un eșantion, iar jocul nu deține un pointer către acea voce, vocea poate fi pusă în coadă pentru a fi eliminată imediat. Dacă jocul deține un pointer, atunci obiectul voce nu trebuie să fie șters. În cazul în care jocul deține un pointer, dar proprietarul pointerului este distrus înainte ca vocea să se termine, vocea trebuie să fie anulată. În loc să adaug complexitate la Reference<>, am decis că este mai practic să introducem în schimb clase de șabloane separate.
95% din timp, reutilizarea codului existent este calea de urmat. Dar dacă începeți să vă simțiți paralizat sau vă treziți că adăugați complexitate la ceva care a fost odată simplu, întrebați-vă dacă ceva din baza de cod ar trebui să fie de fapt două lucruri.
Este în regulă să folosiți convenții de apelare diferite
Un lucru care nu-mi place la Java este că vă obligă să definiți fiecare funcție în interiorul unei clase. Este un nonsens, în opinia mea. S-ar putea să vă facă codul să arate mai coerent, dar încurajează, de asemenea, ingineria excesivă și nu se pretează bine la abordarea iterativă pe care am descris-o mai devreme.
În motorul meu C++, unele funcții aparțin claselor și altele nu. De exemplu, fiecare inamic din joc este o clasă, iar cea mai mare parte a comportamentului inamicului este implementată în interiorul acelei clase, așa cum probabil v-ați aștepta. Pe de altă parte, turnările de sfere din motorul meu sunt efectuate prin apelarea sphereCast(), o funcție din spațiul de nume physics. sphereCast() nu aparține niciunei clase – este doar o parte a modulului physics. Am un sistem de construire care gestionează dependențele dintre module, ceea ce menține codul organizat suficient de bine pentru mine. Înfășurarea acestei funcții în interiorul unei clase arbitrare nu va îmbunătăți organizarea codului în nici un mod semnificativ.
Apoi există dispecerizarea dinamică, care este o formă de polimorfism. Deseori avem nevoie să apelăm o funcție pentru un obiect fără a cunoaște tipul exact al acelui obiect. Primul instinct al unui programator C++ este să definească o clasă de bază abstractă cu funcții virtuale, apoi să suprascrie aceste funcții într-o clasă derivată. Acest lucru este valabil, dar este doar o tehnică. Există și alte tehnici de dispecerizare dinamică care nu introduc la fel de mult cod suplimentar sau care aduc alte beneficii:
- C++11 a introdus
std::function, care este o modalitate convenabilă de a stoca funcțiile callback. Este, de asemenea, posibil să vă scrieți propria versiune destd::functioncare este mai puțin dureroasă pentru a intra în debugger. - Multe funcții callback pot fi implementate cu o pereche de pointeri: Un pointer de funcție și un argument opac. Este nevoie doar de un cast explicit în interiorul funcției de callback. Vedeți acest lucru foarte des în bibliotecile C pure.
- Câteodată, tipul subiacent este de fapt cunoscut în momentul compilării și puteți lega apelul de funcție fără niciun fel de supraîncărcare suplimentară în timpul execuției. Turf, o bibliotecă pe care o folosesc în motorul meu de joc, se bazează foarte mult pe această tehnică. A se vedea
turf::Mutex, de exemplu. Este doar untypedefpeste o clasă specifică platformei. - Câteodată, cea mai simplă abordare este să construiți și să mențineți singur un tabel de pointeri de funcții brute. Am folosit această abordare în mixerul meu audio și în sistemul de serializare. De asemenea, interpretorul Python utilizează intens această tehnică, după cum se menționează mai jos.
- Puteți chiar stoca pointeri de funcție într-un tabel hash, utilizând numele funcțiilor ca chei. Eu folosesc această tehnică pentru a expedia evenimente de intrare, cum ar fi evenimentele multitouch. Face parte dintr-o strategie de înregistrare a intrărilor din joc și de redare a acestora cu un sistem de reluare.
Dynamic dispatch este un subiect mare. Nu fac decât să zgârii suprafața pentru a arăta că există multe moduri de a-l realiza. Cu cât scrieți mai mult cod extensibil de nivel scăzut – ceea ce este obișnuit într-un motor de joc – cu atât mai mult vă veți găsi explorând alternative. Dacă nu sunteți obișnuiți cu acest tip de programare, interpretorul Python, care este scris un C, este o resursă excelentă din care puteți învăța. Acesta implementează un model de obiecte puternic: Fiecare PyObject punctează către un PyTypeObject, iar fiecare PyTypeObject conține un tabel de pointeri de funcții pentru dispecerizare dinamică. Documentul Defining New Types (Definirea de noi tipuri) este un bun punct de plecare dacă doriți să intrați direct în subiect.
Atenție că serializarea este un subiect important
Serializarea este actul de conversie a obiectelor în timp de execuție într-o și dintr-o secvență de octeți. Cu alte cuvinte, salvarea și încărcarea datelor.
Pentru multe, dacă nu chiar majoritatea motoarelor de jocuri, conținutul jocului este creat în diverse formate editabile, cum ar fi .png, .json, .blend sau formate proprietare, apoi, în cele din urmă, este convertit în formate de joc specifice platformei pe care motorul le poate încărca rapid. Ultima aplicație din această filieră este adesea denumită „preparator”. Bucătarul poate fi integrat într-un alt instrument sau chiar distribuit pe mai multe mașini. De obicei, „cooker-ul” și o serie de instrumente sunt dezvoltate și întreținute în tandem cu motorul de joc propriu-zis.
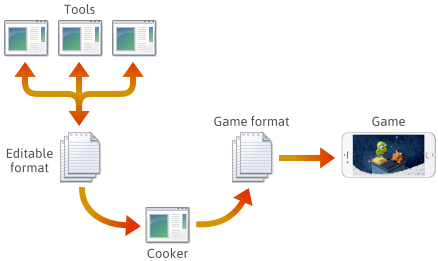
Când configurați o astfel de conductă, alegerea formatului de fișier în fiecare etapă depinde de dumneavoastră. S-ar putea să definiți anumite formate de fișiere proprii, iar aceste formate ar putea evolua pe măsură ce adăugați caracteristici ale motorului. Pe măsură ce evoluează, s-ar putea să considerați că este necesar să păstrați anumite programe compatibile cu fișierele salvate anterior. Indiferent de format, în cele din urmă va trebui să îl serializați în C++.
Există nenumărate moduri de a implementa serializarea în C++. O modalitate destul de evidentă este să adăugați funcțiile load și save la clasele C++ pe care doriți să le serializați. Puteți obține compatibilitate retroactivă prin stocarea unui număr de versiune în antetul fișierului, apoi prin trecerea acestui număr în fiecare funcție load. Acest lucru funcționează, deși codul poate deveni greu de întreținut.
void load(InStream& in, u32 fileVersion) { // Load expected member variables in >> m_position; in >> m_direction; // Load a newer variable only if the file version being loaded is 2 or greater if (fileVersion >= 2) { in >> m_velocity; } }
Este posibil să scrieți un cod de serializare mai flexibil și mai puțin predispus la erori profitând de reflecție – mai exact, prin crearea de date în timp de execuție care descriu dispunerea tipurilor dumneavoastră C++. Pentru o idee rapidă despre modul în care reflecția poate ajuta la serializare, aruncați o privire la modul în care Blender, un proiect open source, o face.
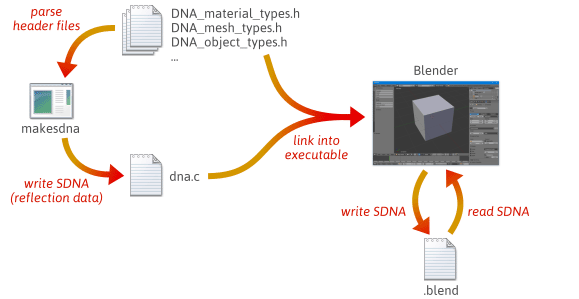
Când construiți Blender din codul sursă, au loc mulți pași. În primul rând, un utilitar personalizat numit makesdna este compilat și rulat. Acest utilitar analizează un set de fișiere de antet C din arborele sursă Blender, apoi produce un rezumat compact al tuturor tipurilor C definite în cadrul acestora, într-un format personalizat cunoscut sub numele de SDNA. Aceste date SDNA servesc drept date de reflecție. SDNA este apoi legat în Blender însuși și salvat cu fiecare fișier .blend pe care Blender îl scrie. Din acel moment, ori de câte ori Blender încarcă un fișier .blend, acesta compară SDNA-ul fișierului .blend cu SDNA-ul legat în versiunea curentă în timpul execuției și utilizează codul de serializare generic pentru a gestiona orice diferențe. Această strategie îi conferă lui Blender un grad impresionant de compatibilitate cu trecutul și cu viitorul. Puteți încărca în continuare fișiere 1.0 în cea mai recentă versiune de Blender, iar noile fișiere .blend pot fi încărcate în versiuni mai vechi.
Ca și Blender, multe motoare de jocuri – și instrumentele asociate acestora – generează și utilizează propriile date de reflectare. Există mai multe moduri de a face acest lucru: Puteți analiza propriul cod sursă C/C++ pentru a extrage informațiile de tip, așa cum face Blender. Puteți crea un limbaj separat de descriere a datelor și puteți scrie un instrument care să genereze definiții de tip C++ și date de reflecție din acest limbaj. Puteți utiliza macro-uri de preprocesor și șabloane C++ pentru a genera date de reflecție în timpul execuției. Și, odată ce aveți datele de reflecție disponibile, există nenumărate modalități de a scrie un serializator generic deasupra acestora.
Evident, omit o mulțime de detalii. În această postare, vreau doar să arăt că există multe moduri diferite de serializare a datelor, dintre care unele sunt foarte complexe. Programatorii pur și simplu nu discută despre serializare la fel de mult ca despre alte sisteme de motoare, chiar dacă majoritatea celorlalte sisteme se bazează pe ea. De exemplu, din cele 96 de discuții despre programare ținute la GDC 2017, am numărat 31 de discuții despre grafică, 11 despre online, 10 despre instrumente, 4 despre AI, 3 despre fizică, 2 despre audio – dar doar una care a atins direct serializarea.
At least, încercați să aveți o idee despre cât de complexe vor fi nevoile dvs. Dacă faceți un joc micuț precum Flappy Bird, cu doar câteva active, probabil că nu trebuie să vă gândiți prea mult la serializare. Probabil că puteți încărca texturi direct din PNG și va fi bine. Dacă aveți nevoie de un format binar compact cu compatibilitate retroactivă, dar nu doriți să vă dezvoltați propriul format, aruncați o privire la biblioteci terțe, cum ar fi Cereal sau Boost.Serialization. Nu cred că Google Protocol Buffers sunt ideale pentru serializarea activelor de joc, dar merită totuși studiate.
Scrierea unui motor de joc – chiar și a unuia mic – este o întreprindere mare. Aș putea spune mult mai multe despre asta, dar pentru o postare de această lungime, acesta este, sincer, cel mai util sfat pe care mă pot gândi să-l dau: Lucrați iterativ, rezistați impulsului de a unifica puțin codul și să știți că serializarea este un subiect important, astfel încât să puteți alege o strategie adecvată. Din experiența mea, fiecare dintre aceste lucruri poate deveni o piatră de poticnire dacă este ignorat.
Îmi place să compar notițe despre aceste lucruri, așa că aș fi foarte interesat să aud părerile altor dezvoltatori. Dacă ați scris un motor, experiența dvs. v-a condus la aceleași concluzii? Iar dacă nu ați scris unul, sau doar vă gândiți la asta, mă interesează și părerile voastre. Ce considerați că este o resursă bună din care să învățați? Ce părți vi se par încă misterioase? Nu ezitați să lăsați un comentariu mai jos sau să mă contactați pe Twitter!
.