Lately I’ve been writing a game engine in C++. Estou usando-o para fazer um pequeno jogo para celular chamado Hop Out. Aqui está um clipe capturado do meu iPhone 6. (Sem som!)

Hop Out é o tipo de jogo que eu quero jogar: Jogo de arcade retro com um visual de desenhos animados 3D. O objetivo é mudar a cor de cada bloco, como em Q*Bert.
Hop Out ainda está em desenvolvimento, mas a engine que o alimenta está começando a ficar bastante madura, então eu pensei em compartilhar algumas dicas sobre o desenvolvimento da engine aqui.
Por que você gostaria de escrever uma engine de jogo? Há muitas razões possíveis:
- Você é um funileiro. Você adora construir sistemas desde o início e vê-los ganhar vida.
- Você quer aprender mais sobre o desenvolvimento de jogos. Eu passei 14 anos na indústria de jogos e eu ainda estou descobrindo. Eu nem tinha certeza se conseguiria escrever uma engine do zero, já que é muito diferente das responsabilidades diárias de um trabalho de programação em um grande estúdio. Eu queria descobrir.
- Você gosta de controle. É satisfatório organizar o código exatamente do jeito que você quer, sabendo onde tudo está o tempo todo.
- Você se sente inspirado por engines de jogos clássicos como AGI (1984), id Tech 1 (1993), Build (1995), e gigantes da indústria como Unity e Unreal.
- Você acredita que nós, a indústria de jogos, devemos tentar desmistificar o processo de desenvolvimento da engine. Não é como se nós tivéssemos dominado a arte de fazer jogos. Longe disso! Quanto mais examinamos este processo, maiores são as nossas chances de melhorar nele.
As plataformas de jogo de 2017 – móvel, console e PC – são muito poderosas e, em muitos aspectos, bastante semelhantes entre si. O desenvolvimento do motor de jogo não se trata tanto de lutar com hardware fraco e exótico, como era no passado. Na minha opinião, trata-se mais de lutar com a complexidade da sua própria criação. É fácil criar um monstro! É por isso que o conselho neste post centra-se em manter as coisas manejáveis. Eu o organizei em três seções:
- Use uma abordagem iterativa
- Pense duas vezes antes de unificar demais as coisas
- Esteja ciente de que a serialização é um grande assunto
Este conselho se aplica a qualquer tipo de mecanismo de jogo. Eu não vou te dizer como escrever um shader, o que é um octree, ou como adicionar a física. Esses são os tipos de coisas que, presumo, você já sabe que deve saber – e depende muito do tipo de jogo que você quer fazer. Em vez disso, eu escolhi deliberadamente pontos que não parecem ser amplamente reconhecidos ou falados – estes são os tipos de pontos que eu acho mais interessantes quando tento desmistificar um assunto.
Utilizar uma Abordagem Iterativa
O meu primeiro conselho é conseguir algo (qualquer coisa!) rodando rapidamente, depois iterar.
Se possível, comece com uma aplicação de exemplo que inicializa o dispositivo e desenha algo na tela. No meu caso, eu baixei o SDL, abri o Xcode-iOS/Test/TestiPhoneOS.xcodeproj, depois executei o testgles2 sample no meu iPhone.

Voilà! Eu tinha um lindo cubo girando usando OpenGL ES 2.0.
Meu próximo passo foi baixar um modelo 3D que alguém fez de Mario. Eu escrevi um rápido & dirty OBJ file loader – o formato do arquivo não é tão complicado – e hackeei a aplicação de exemplo para renderizar o Mario ao invés de um cubo. Também integrei SDL_Image para ajudar a carregar texturas.

Então implementei controles dual-stick para mover o Mario de um lado para o outro. (No início, eu estava pensando em fazer um atirador dual-stick. Mas não com o Mario.)

Próximo, eu queria explorar animação esquelética, então eu abri o Blender, modelei um tentáculo, e o manipulei com um esqueleto de dois ossos que balançava para frente e para trás.
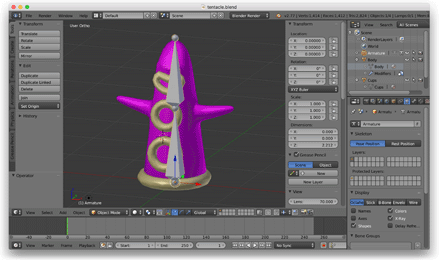
Neste ponto, eu abandonei o formato de arquivo OBJ e escrevi um script Python para exportar arquivos JSON personalizados do Blender. Esses arquivos JSON descreveram a malha skinned, o esqueleto e os dados de animação. Eu carreguei esses arquivos no jogo com a ajuda de uma biblioteca C++ JSON.

Após isso ter funcionado, eu voltei ao Blender e fiz um personagem mais elaborado. (Este foi o primeiro humano 3D que eu criei. Fiquei bastante orgulhoso dele.)

Nos meses seguintes, dei os seguintes passos:
- Iniciei o factoring das funções vector e matriz na minha própria biblioteca matemática 3D.
- Substitui o
.xcodeprojpor um projeto CMake. - Põe o motor em funcionamento tanto no Windows como no iOS, porque gosto de trabalhar no Visual Studio.
- Iniciei o código móvel em bibliotecas separadas de “motor” e “jogo”. Com o tempo, eu dividi essas bibliotecas em bibliotecas ainda mais granulares.
- Escrevi uma aplicação separada para converter meus arquivos JSON em dados binários que o jogo pode carregar diretamente.
- Retirar todas as bibliotecas SDL da compilação do iOS. (A compilação do Windows ainda usa o SDL.)
O ponto é: Eu não planejei a arquitetura do motor antes de começar a programar. Esta foi uma escolha deliberada. Ao invés disso, eu apenas escrevi o código mais simples que implementou o próximo recurso, então eu olharia para o código para ver que tipo de arquitetura emergiu naturalmente. Por “engine architecture”, quero dizer o conjunto de módulos que compõem a engine do jogo, as dependências entre esses módulos, e a API para interagir com cada módulo.
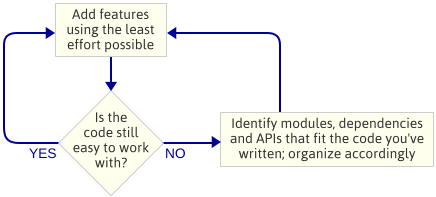
Esta é uma abordagem iterativa porque foca em produtos menores. Funciona bem quando se escreve um motor de jogo porque, a cada passo no caminho, você tem um programa em execução. Se algo der errado quando você está fatorando o código em um novo módulo, você sempre pode comparar suas mudanças com o código que funcionou anteriormente. Obviamente, eu assumo que você está usando algum tipo de controle de código fonte.
Você pode pensar que muito tempo é desperdiçado nesta abordagem, já que você está sempre escrevendo código ruim que precisa ser limpo mais tarde. Mas a maior parte da limpeza envolve mover o código de um arquivo .cpp para outro, extraindo declarações de funções para arquivos .h, ou mudanças igualmente simples. Decidir para onde as coisas devem ir é a parte mais difícil, e isso é mais fácil de fazer quando o código já existe.
Eu argumentaria que mais tempo é desperdiçado na abordagem oposta: Tentando muito para criar uma arquitetura que faça tudo o que você acha que vai precisar antes do tempo. Dois dos meus artigos favoritos sobre os perigos da superengenharia são The Vicious Circle of Generalization de Tomasz Dąbrowski e Don’t Let Architecture Astronauts Scare You de Joel Spolsky.
Não estou dizendo que você nunca deve resolver um problema no papel antes de resolvê-lo em código. Eu também não estou dizendo que você não deve decidir com antecedência quais características você quer. Por exemplo, eu sabia desde o início que queria que meu motor carregasse todos os recursos em uma linha de fundo. Eu só não tentei desenhar ou implementar essa funcionalidade até o meu motor carregar alguns activos primeiro.
A abordagem iterativa deu-me uma arquitectura muito mais elegante do que alguma vez poderia ter sonhado ao olhar para uma folha de papel em branco. A construção do iOS do meu motor é agora 100% código original incluindo uma biblioteca matemática personalizada, modelos de contentores, sistema de reflexão/serialização, estrutura de renderização, física e mixer de áudio. Eu tinha razões para escrever cada um desses módulos, mas você pode não achar necessário escrever todas essas coisas sozinho. Existem muitas bibliotecas de código aberto grandes, permissivamente licenciadas, que você pode achar apropriado para o seu motor. GLM, Bullet Physics e os cabeçalhos STB são apenas alguns exemplos interessantes.
Pense Duas Vezes Antes de Unificar Demasiadas Coisas
Como programadores, tentamos evitar a duplicação de código, e gostamos quando o nosso código segue um estilo uniforme. No entanto, acho que é bom não deixar que esses instintos se sobreponham a cada decisão.
Resistam ao Princípio DRY De vez em quando
Para dar um exemplo, o meu motor contém várias classes de modelos “smart pointer”, semelhantes em espírito a std::shared_ptr. Cada uma delas ajuda a prevenir vazamentos de memória, servindo como um invólucro em torno de um ponteiro bruto.
-
Owned<>é para objetos alocados dinamicamente que têm um único dono. -
Reference<>usa contagem de referência para permitir que um objeto tenha vários donos. -
audio::AppOwned<>é usado por código fora do mixer de áudio. Ele permite que sistemas de jogo possuam objetos que o mixer de áudio usa, como uma voz que está tocando atualmente. -
audio::AudioHandle<>usa um sistema de contagem de referência interno ao mixer de áudio.
Pode parecer que algumas dessas classes duplicam a funcionalidade das outras, violando o Princípio DRY (Don’t Repeat Yourself). Na verdade, no início do desenvolvimento, tentei reutilizar a classe Reference<> existente, tanto quanto possível. Entretanto, descobri que a vida útil de um objeto de áudio é regida por regras especiais: Se uma voz de áudio tiver terminado de reproduzir uma amostra, e o jogo não segurar um ponteiro para essa voz, a voz pode ser enfileirada para eliminação imediata. Se o jogo tiver um ponteiro, então o objecto de voz não deve ser apagado. E se o jogo segurar um ponteiro, mas o dono do ponteiro for destruído antes da voz ter terminado, a voz deve ser cancelada. Em vez de adicionar complexidade a Reference<>, decidi que era mais prático introduzir classes de modelos separadas.
95% do tempo, reutilizar o código existente é o caminho a seguir. Mas se você começar a se sentir paralisado, ou se encontrar adicionando complexidade a algo que já foi simples, pergunte-se se algo na base de código deveria ser realmente duas coisas.
Não há problema em usar convenções de chamadas diferentes
Uma coisa que eu não gosto em Java é que ele força você a definir cada função dentro de uma classe. Isso é um disparate, na minha opinião. Pode fazer o seu código parecer mais consistente, mas também encoraja a super-engenharia e não se presta bem à abordagem iterativa que descrevi anteriormente.
No meu motor C++, algumas funções pertencem a classes e outras não. Por exemplo, cada inimigo no jogo é uma classe, e a maioria do comportamento do inimigo é implementado dentro dessa classe, como você provavelmente esperaria. Por outro lado, os moldes de esfera no meu motor são executados chamando sphereCast(), uma função no espaço de nomes physics. sphereCast() não pertence a nenhuma classe – é apenas parte do módulo physics. Eu tenho um sistema de compilação que gerencia as dependências entre módulos, o que mantém o código bem organizado o suficiente para mim. Embrulhar esta função dentro de uma classe arbitrária não vai melhorar a organização do código de forma significativa.
Então há um despacho dinâmico, que é uma forma de polimorfismo. Muitas vezes precisamos chamar uma função para um objeto sem saber o tipo exato desse objeto. O primeiro instinto de um programador em C++ é definir uma classe base abstrata com funções virtuais, e depois sobrepor essas funções em uma classe derivada. Isso é válido, mas é apenas uma técnica. Existem outras técnicas de despacho dinâmico que não introduzem tanto código extra, ou que trazem outros benefícios:
- C++11 introduzido
std::function, que é uma forma conveniente de armazenar funções de callback. Também é possível escrever a sua própria versão destd::function, o que é menos doloroso de entrar no depurador. - Muitas funções de callback podem ser implementadas com um par de apontadores: Um ponteiro de função e um argumento opaco. Só requer um elenco explícito dentro da função de callback. Você vê isto muito em bibliotecas C puras.
- Por vezes, o tipo subjacente é realmente conhecido em tempo de compilação, e você pode ligar a chamada de função sem qualquer sobrecarga adicional de tempo de execução. Turf, uma biblioteca que eu uso no meu motor de jogo, depende muito desta técnica. Veja
turf::Mutexpor exemplo. É apenas umtypedefsobre uma classe específica de plataforma. - Por vezes, a abordagem mais directa é construir e manter uma tabela de apontadores de funções em bruto você mesmo. Eu usei esta abordagem no meu mixer de áudio e sistema de serialização. O interpretador Python também faz uso pesado desta técnica, como mencionado abaixo.
- Vocês podem até armazenar ponteiros de funções em uma tabela hash, usando os nomes das funções como chaves. Eu uso esta técnica para enviar eventos de entrada, tais como eventos multitouch. É parte de uma estratégia para gravar entradas de jogo e jogá-las de volta com um sistema de replay.
O despacho dinâmico é um grande assunto. Eu só estou arranhando a superfície para mostrar que há muitas maneiras de alcançá-lo. Quanto mais você escrever código de baixo nível extensível – o que é comum em um mecanismo de jogo – mais você vai se encontrar explorando alternativas. Se não está habituado a este tipo de programação, o intérprete Python, que é escrito em C, é um excelente recurso com o qual pode aprender. Ele implementa um poderoso modelo de objeto: Cada PyObject aponta para um PyTypeObject, e cada PyTypeObject contém uma tabela de apontadores de funções para envio dinâmico. O documento Definindo Novos Tipos é um bom ponto de partida se você quiser pular direto em.
Cuidado de que a serialização é um grande assunto
Serialização é o ato de converter objetos em tempo de execução de e para uma seqüência de bytes. Em outras palavras, salvando e carregando dados.
Para muitos se não a maioria das engine de jogos, o conteúdo do jogo é criado em vários formatos editáveis como .png, .json, .blend ou formatos proprietários, então eventualmente convertidos para formatos de jogos específicos da plataforma que a engine pode carregar rapidamente. A última aplicação neste pipeline é frequentemente referida como um “cooker”. O fogão pode ser integrado em outra ferramenta, ou mesmo distribuído em várias máquinas. Normalmente, o fogão e uma série de ferramentas são desenvolvidos e mantidos em conjunto com a própria engine do jogo.
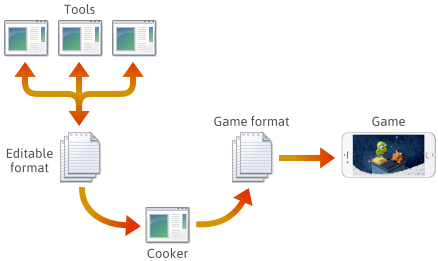
Ao configurar tal pipeline, a escolha do formato de arquivo em cada etapa é da sua responsabilidade. Você pode definir alguns formatos de arquivo próprios, e esses formatos podem evoluir à medida que você adiciona funcionalidades do mecanismo. À medida que eles evoluem, você pode achar necessário manter certos programas compatíveis com arquivos salvos anteriormente. Não importa qual formato, você precisará, em última instância, serializá-lo em C++.
Existem inúmeras maneiras de implementar a serialização em C++. Uma forma bastante óbvia é adicionar load e save funções às classes C+++ que você deseja serializar. Você pode conseguir compatibilidade retroativa armazenando um número de versão no cabeçalho do arquivo, depois passando este número para cada função load. Isto funciona, embora o código possa tornar-se complicado de manter.
void load(InStream& in, u32 fileVersion) { // Load expected member variables in >> m_position; in >> m_direction; // Load a newer variable only if the file version being loaded is 2 or greater if (fileVersion >= 2) { in >> m_velocity; } }
É possível escrever um código de serialização mais flexível e menos sujeito a erros, aproveitando a reflexão – especificamente, criando dados em tempo de execução que descrevem o layout dos seus tipos de C++. Para uma rápida idéia de como a reflexão pode ajudar na serialização, dê uma olhada em como o Blender, um projeto de código aberto, o faz.
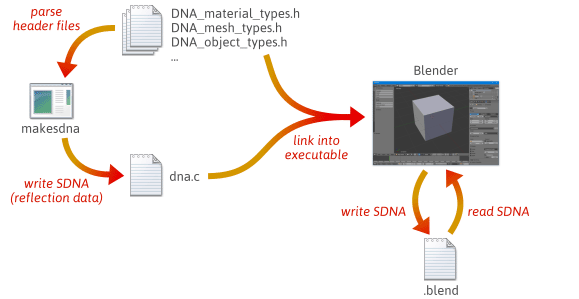
Quando você constrói o Blender a partir do código fonte, muitos passos acontecem. Primeiro, um utilitário personalizado chamado makesdna é compilado e executado. Este utilitário analisa um conjunto de arquivos de cabeçalho C na árvore de código fonte do Blender, e então produz um resumo compacto de todos os tipos C definidos dentro dele, em um formato personalizado conhecido como SDNA. Estes dados SDNA servem como dados de reflexão. O SDNA é então ligado ao próprio Blender, e salvo com cada .blend arquivo que o Blender escreve. A partir daí, sempre que o Blender carrega um arquivo .blend, ele compara o SDNA do arquivo .blend com o SDNA ligado à versão atual em tempo de execução, e usa código genérico de serialização para lidar com quaisquer diferenças. Esta estratégia dá ao Blender um grau impressionante de compatibilidade para frente e para trás. Você ainda pode carregar arquivos 1.0 na última versão do Blender, e novos arquivos .blend podem ser carregados em versões anteriores.
Like Blender, muitos mecanismos de jogo – e suas ferramentas associadas – geram e usam seus próprios dados de reflexão. Há muitas maneiras de fazer isso: Você pode analisar seu próprio código fonte C/C++ para extrair informações do tipo, como faz o Blender. Você pode criar uma linguagem de descrição de dados separada, e escrever uma ferramenta para gerar definições de tipo C++ e dados de reflexão a partir desta linguagem. Você pode usar macros pré-processadoras e modelos C++ para gerar dados de reflexão em tempo de execução. E uma vez que você tenha dados de reflexão disponíveis, há inúmeras maneiras de escrever um serializador genérico em cima dele.
Claramente, eu estou omitindo muitos detalhes. Neste post, eu só quero mostrar que existem muitas formas diferentes de serializar dados, algumas das quais são muito complexas. Os programadores simplesmente não discutem a serialização tanto quanto outros sistemas de motores, mesmo que a maioria dos outros sistemas confiem nela. Por exemplo, das 96 palestras de programação dadas no GDC 2017, eu contei 31 palestras sobre gráficos, 11 sobre online, 10 sobre ferramentas, 4 sobre IA, 3 sobre física, 2 sobre áudio – mas apenas uma que tocou diretamente na serialização.
No mínimo, tente ter uma idéia de quão complexas serão suas necessidades. Se você está fazendo um pequeno jogo como o Flappy Bird, com apenas alguns recursos, você provavelmente não precisa pensar muito sobre serialização. Você provavelmente pode carregar texturas diretamente da PNG e tudo ficará bem. Se você precisa de um formato binário compacto com compatibilidade retroativa, mas não quer desenvolver o seu próprio, dê uma olhada em bibliotecas de terceiros, como a Cereal ou a Boost.Serialization. Eu não acho que os Buffers de Protocolo do Google sejam ideais para a serialização dos ativos do jogo, mas vale a pena estudá-los.
Escrever um mecanismo de jogo – mesmo um pequeno – é uma grande tarefa. Há muito mais que eu poderia dizer sobre isso, mas para um post desse tamanho, esse é honestamente o conselho mais útil que eu posso pensar em dar: Trabalhe iterativamente, resista um pouco ao impulso de unificar o código e saiba que a serialização é um assunto grande para que possa escolher uma estratégia apropriada. Na minha experiência, cada uma dessas coisas pode tornar-se um obstáculo se ignoradas.
Eu adoro comparar notas sobre essas coisas, então eu estaria realmente interessado em ouvir de outros desenvolvedores. Se você escreveu um motor, a sua experiência o levou a alguma das mesmas conclusões? E se você não escreveu uma, ou está apenas pensando sobre isso, eu também estou interessado em seus pensamentos. O que você considera um bom recurso para aprender? Que partes ainda lhe parecem misteriosas? Sinta-se à vontade para deixar um comentário abaixo ou me dar um hit up no Twitter!